This week’s classic pick is Joe Armstrong’s 2014 Strange Loop talk The Mess We’re In — a 45-minute polemic from the co-creator of Erlang on why software is getting worse, what the laws of physics say about how fast computation could be, and how we should stop using human-chosen file names. Armstrong died in 2019, but the talk has aged remarkably well: in the era of 128-parallel coding agents, his entropy critique reads less like nostalgia and more like a warning we’ve kept ignoring.
The opening anecdote (and the actual thesis)
Armstrong tells the story of a bad Friday: an OpenOffice update lost all the images in his slides, an Apple Keynote upgrade silently broke his cross-laptop workflow, and an attempt to fall back to HTML slideshows died on unable to find local Grunt. He gives up. That’s the title of the talk — the mess we’re in. The rest is an inquiry into what went wrong and why.
The thesis: the entropy of software increases with time. We can do amazing things with computers when they work, but when they don’t, we no longer understand why. Thirty years ago a broken program was something you read. Today a broken program is something you Google.

The historical frame
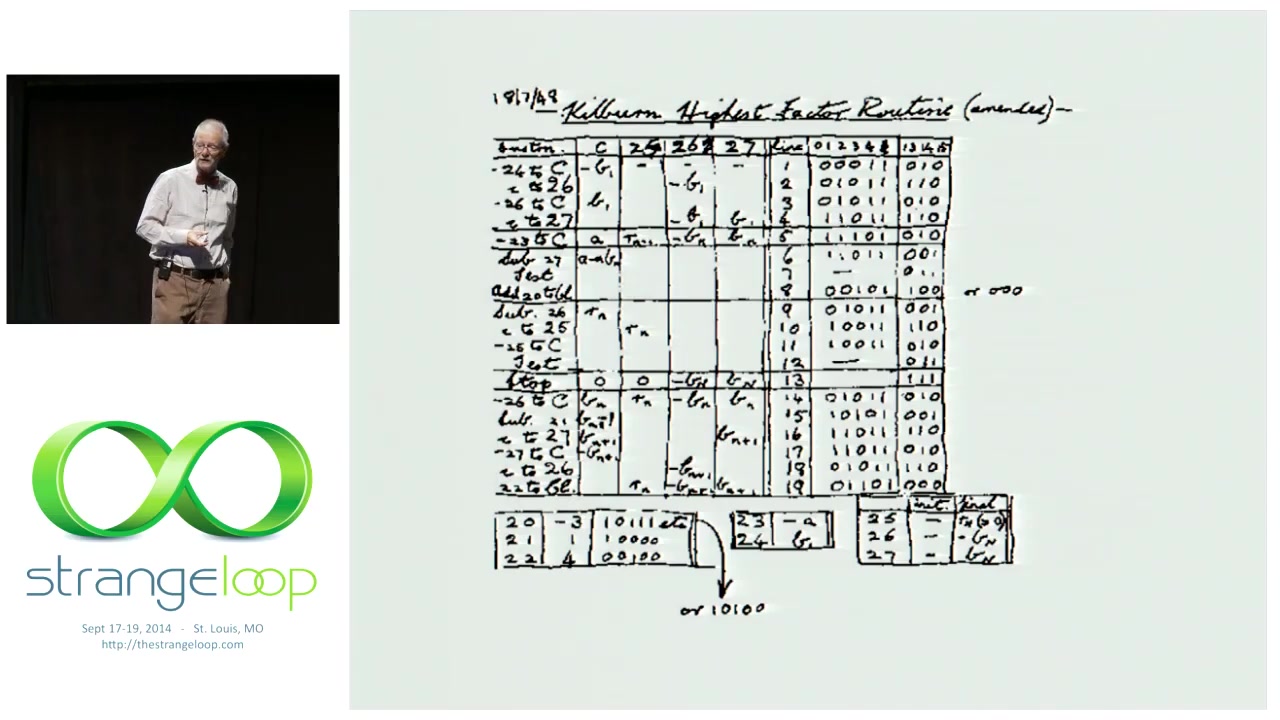
Armstrong’s frame is generational: in 1948 Tom Kilburn ran the first stored program ever on a Williams-tube cathode-ray-tube memory holding 64 words of 32 bits. “Probably the last program that was totally correct.” By 1985 (when Armstrong started work on Erlang), a typical computer had 254 KB of memory and an 8 MHz clock. Today’s laptops have ~30,000× the memory and ~1,000× the clock speed — so why don’t they boot in 60 milliseconds? Where did the speedup go?

Why state space breaks our intuitions
The most-cited section of the talk is Armstrong’s back-of-envelope on state space. The number of atoms on Earth is roughly 10⁵⁰. Solving 2^K = 10^50 gives K ≈ 166. Divided by 32, that’s about six 32-bit integers — the number of states reachable by six C variables equals the number of atoms on the planet. (For JavaScript’s wider variable types, it’s three.)
His laptop has 250 GB of flash, putting its total state at roughly 2²⁰⁰⁰⁰⁰⁰⁰⁰⁰⁰ — vastly more than the number of atoms in the observable universe. So when you search Stack Overflow for someone with “exactly the same problem” and the fix doesn’t work for you, the answer is not magic: it’s that your machine’s state and theirs differ in some of those astronomically many dimensions.
“There just isn’t another machine on the planet that is in the same state as yours.”


The seven (twenty-five) deadly sins
Armstrong drafted “seven deadly sins of programming” on the Underground and ended up with 25 before he got off. The headline ones:
- No comments. No specification. Code you can’t understand a week later.
- Notation churn — three languages to learn in 1985 (shell, make, C) versus thousands today, with no shared lingua franca.
- Build-tool sprawl: ant, grunt, make, rake, maven, jake, bake, fabric, paper, shovel. “Is there a rake equivalent in Python?” leads to invoke, fabric, paver, doit — and none of them are good answers.
- Programming without Google or Stack Overflow is now nearly impossible. He challenges the audience to code offline for more than five minutes.
What physics says about how fast we could compute
Armstrong was a physicist before he was a programmer, and the middle of the talk is a delightful detour into quantum limits:
- Bremermann’s limit: 1.36 × 10⁵⁰ Hz per kilogram — the maximum clock rate matter can sustain.
- Margolus–Levitin theorem: ~10³³ operations per second per joule.
- Bekenstein bound: ~2 × 10⁴³ bits per kg per meter of radius.
- Landauer’s limit: the minimum energy to flip one bit.
If you let weight go to 1 kg and squash components together hard enough, the ultimate computer is a 1-kg black hole: ~10⁵¹ ops/sec, ~10⁻²⁷ m across, lifetime ~10⁻²¹ seconds, with output via Hawking radiation and quantum entanglement. Even more dramatic: the entire observable universe, treated as a single supercomputer, has executed roughly 10¹²³ operations since the Big Bang. Useful number for cryptographers — anything requiring more is uncrackable by the universe itself.
The gap between what’s physically possible (~10⁵¹ ops/sec on 10³¹ bits) and what conventional computers achieve (~10ⁿ ops on 10¹² bits) is the room for improvement that, Armstrong notes, software architecture is doing nothing to take advantage of.

Distributed-systems realism (and what RAFT-style designs ignore)
The middle of the talk is Armstrong applying physics to distributed systems. A short list of things software pretends are free but aren’t:
- Causality. Information propagates via light/sound. Until a message arrives, the recipient doesn’t know what happened.
- Replicated consistent data. “This breaks the laws of physics.” Two-phase commit “breaks the laws of physics.” Byzantine generals is a fact about the world, not a design choice.
- Simultaneity. Two stars exploding “at the same time” is observer-relative. Distributed systems that ignore this hit big problems.
To tolerate failure you need not one machine but two, ten, fifty — replicated and independent — and you can drive the joint failure rate arbitrarily low. But to write such systems you must accept distributed and concurrent programming as the only way forward.
The condenser: abolish names, use hashes
The constructive proposal in the final third is what makes the talk worth re-watching in 2026. Armstrong argues we should abolish file names and locations and identify everything by a hash of its content:
- Names are imprecise. URIs are bad — they need DNS (spoofable), point to a specific host (which might be down), break when the content changes, can’t be cached safely.
- Content-addressable storage is better. Compute SHA-1 of the blob; that’s the name. Cacheable forever. Man-in-the-middle attacks can’t change content silently because you re-verify the hash. No naming conflicts.
- To find a blob, use a self-organizing distributed hash table — Kademlia, Chord. Hash machine IPs, sort them, route lookups to the machines whose hashes bracket the target. The exact mechanism behind BitTorrent’s DHT and (Armstrong half-jokingly proposes) “git-torrent.”

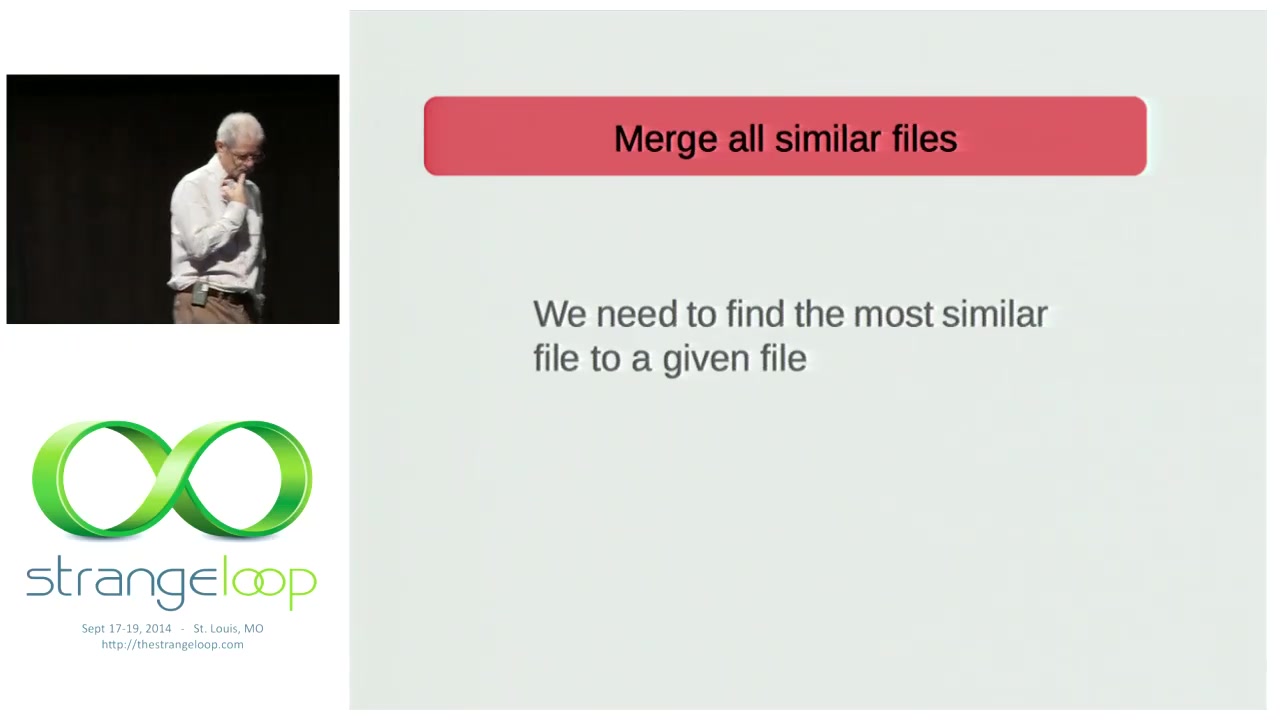
Reducing entropy: the condenser
Armstrong owns 85,000 Erlang modules on his machine — many of them probably near-duplicates. He proposes the condenser: a globally distributed sausage machine into which you push all files and out of which falls only the irreducible kernel. Step one is easy:
for f in all_files_on_the_planet:
c = content_of(f)
key = sha1(c)
store(key, c) in global_distributed_kv
That collapses identical files. Step two — finding similar files — is the open problem he’s been working on for twenty years with “embarrassingly small progress.” His current technique: least compression difference. If compress(A ++ B) is barely larger than compress(A), A and B are similar. Works for small structures, fails for big programs where variable renames break the encoding. Latent Dirichlet allocation, Bayesian inference — there are other techniques, but none cheap enough to run across a planetary corpus.
Closing reading list
Armstrong’s closing list of what needs to happen:
- Computing is about controlling complexity. Dijkstra’s words; we have failed miserably.
- The brain handles ~128 KB of stuff. Build reliable systems out of small validated units.
- Reverse entropy. GitHub clones things and grows. We need machinery that shrinks things.
- Be aware of quantum-mechanical upper bounds, and of how astronomical the state space of even tiny programs is.
- Abolish names and places. Replace them with hashes and global DHTs.
- Build lower-power computers. Datacenters now use more energy than aviation. Aviation can’t go to ultra-low power; computers can.
Key takeaways
- Software entropy increases with time. When programs break we no longer read them — we Google them, and the universe is too big for someone else’s machine state to match ours.
- State space is unimaginably large. Six 32-bit C variables can be in as many states as there are atoms on Earth.
- Physical limits are very far away. Bremermann’s limit allows ~10⁵¹ ops/sec/kg; conventional computers do ~10¹⁰. Most of the gap is architectural.
- Two-phase commit “breaks the laws of physics.” Distributed consistency is the Byzantine generals problem, not a configuration option.
- Replace names with hashes. Content-addressable storage plus a Kademlia-style DHT removes the entire class of broken-link / spoofed-DNS / cache-invalidation problems.
- Build a condenser. Identical-file dedup is trivial; similar-file dedup is a 20-year open problem worth attacking.
- Computing is now an environmental threat. Lower-energy computation needs to be a first-class concern.
- Modular, validated, small units. The only way to scale reliable systems is composition of pieces small enough for one mind to verify.
Source
- Talk: “The Mess We’re In”
- Speaker: Joe Armstrong (co-creator of Erlang)
- Conference: Strange Loop 2014
- Duration: ~46 min
- URL: https://www.youtube.com/watch?v=lKXe3HUG2l4