Sparse Notes
Technical notes on DevOps, Kubernetes, Software Engineering, and AI.

In 2014 at NeurIPS in Montreal, Ilya Sutskever, Oriol Vinyals, and Quoc Le presented “Sequence to Sequence Learning with Neural Networks” — the paper that showed encoder–decoder LSTMs could translate French to English end-to-end and, in doing so, planted the seed of the scaling hypothesis. In December 2024 the paper won the NeurIPS Test of Time Award and Sutskever came back on stage to look at that decade with 10 more years of hindsight....

Jason Lopatecki, founder of Arize, opens by noting that his own team’s first agent “frankly sucked” — and that everything they’ve built since is downstream of debugging that failure in production. His AI Engineer talk lays out a concrete pattern for agents that repair themselves: production signal (traces, evals, human labels) feeds a second agent that opens pull requests against the first agent’s own prompts, tools, and skills. It’s the operational shape of the “self-improving system” idea, minus the hand-waving....
Weekly Paper Notes — one of the top picks from the 2026-07-25 CS paper digest. Area: AI / ML (Agent Training). Authors: Xiao Yu, Baolin Peng, Ruize Xu et al. arXiv: 2607.21557 · PDF TL;DR Modern agents are shaped less by their base model and more by the harness wrapped around it — Claude Code, Codex, OpenClaw, GUI-use scaffolds. But those harnesses are stateful, multi-process, and full of tool orchestration, which means existing open SFT/RL stacks (veRL, TRL, OpenRLHF) can’t natively express a rollout inside one....
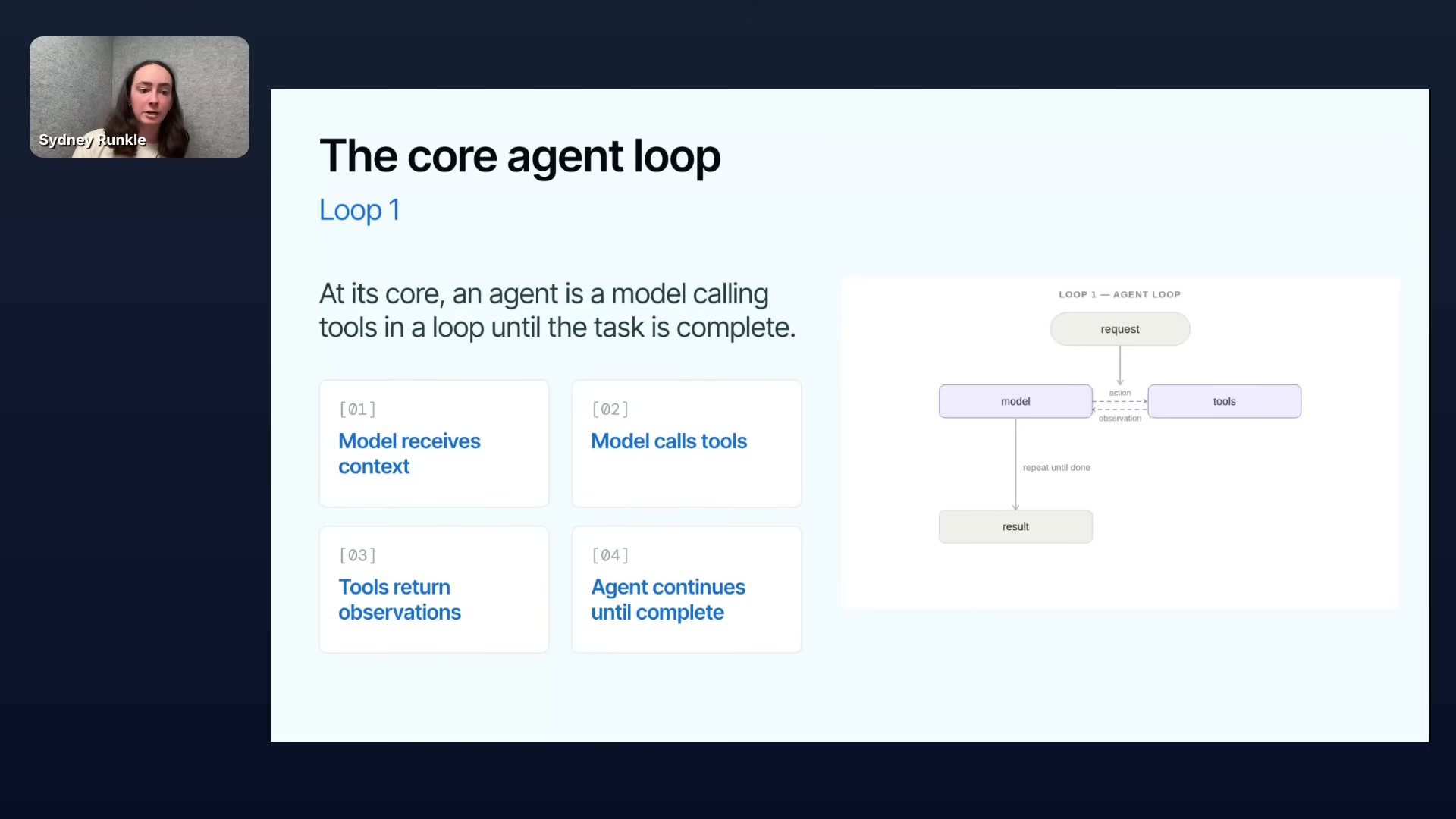
Prompt engineering was the primitive of 2023, context engineering owned 2024–2025, and 2026 is settling on a new one: loop engineering — the discipline of designing the feedback loops that surround an agent, not just the agent itself. Sydney Runkle (PM on LangChain’s open-source team) makes the case in this webinar that the durable advantage is never the agent, it’s the loops built around it. Why loops, not agents Runkle opens with a simple framing: a model has some fixed level of intelligence; a harness wrapped around it converts that intelligence into useful work on a specific problem....

Weekly Paper Notes — 🔁 Seminal Paper of the Week for the 2026-07-25 CS paper digest. Area: Distributed Computing. Authors: Leslie Lamport, Robert Shostak, Marshall Pease (SRI International) Venue: ACM Transactions on Programming Languages and Systems, Vol. 4, No. 3, July 1982, pp. 382–401. DOI: 10.1145/357172.357176 · PDF (SRI copy) Why the paper still matters Almost every distributed system in production today — Spanner, etcd, ZooKeeper, Kafka, every blockchain, every consensus protocol with a Greek letter in its name — is a descendant of the impossibility and possibility results in this 20-page paper....
Weekly Paper Notes — one of the top picks from the 2026-07-25 CS paper digest. Area: NLP / LLM Inference. Author: Alagappan Valliappan arXiv: 2607.21535 · PDF TL;DR Frontier LLMs increasingly ship a built-in Multi-Token-Prediction (MTP / NEXTN) draft head for speculative decoding, based on the assumption that the draft is negligibly cheap. Windowed-MTP shows that assumption breaks catastrophically at million-token context: the native MTP head does full attention over the entire KV cache at every draft step, so its cost grows linearly with context and comes to dominate — precisely where speculation is supposed to matter most....
arXiv: 2607.13276 · PDF: 2607.13276.pdf Authors: Marc Brooker, Marc Bowes, et al. (Amazon Web Services) TL;DR Aurora DSQL is AWS’s new serverless, PostgreSQL-compatible OLTP database designed for multi-region active-active writes. The architecture disaggregates compute (Firecracker MicroVMs running stateless SQL), storage, and transaction coordination into independent horizontally-scalable services. It uses MVCC with precision timestamps for coordination-free reads and optimistic concurrency control for writes, deferring all coordination to commit time via distributed adjudicators and a Journal replication tier....

Agent “skills” — reusable folders of instructions, scripts, and assets that a model loads on demand — have quietly become the packaging unit of the agent ecosystem. Philipp Schmid opens this AI Engineer talk with a brutal statistic from Skills Bench v1.1: of 50,000+ published skills, almost none have evals. Most were AI‑written and never tested. And because agents are non‑deterministic, without evals you have no way to tell whether a failing task is your skill’s fault, the model’s fault, or just noise....
Original: Leslie Lamport, Paxos Made Simple, ACM SIGACT News 32(4), December 2001. Canonical PDF: lamport.azurewebsites.net/pubs/paxos-simple.pdf Predecessor: The Part-Time Parliament, ACM TOCS 16(2), 1998 (the “island of Paxos” allegory that nobody could read). Why “made simple” Lamport originally described his consensus algorithm in 1998 in The Part-Time Parliament, a paper framed as archaeological reconstruction of the parliamentary procedures of an ancient Greek island. It was a joke. It was also, by broad consensus (pun deliberate), unreadable — reviewers hated it, adoption was near zero for years, and even engineers who wanted to build on it complained they couldn’t....
arXiv: 2607.15267 · PDF: 2607.15267.pdf Authors: Victoria Graf, Hannaneh Hajishirzi, et al. TL;DR Prior work on pretraining-data poisoning has mostly targeted curated sources like Wikipedia — a poor stand-in for the scale and heterogeneity of real pretraining corpora. This paper demonstrates that public discussion interfaces on the open web (comment sections, forums, Q&A pages) are a viable at-scale injection vector, and introduces HalfLife, an analysis technique for estimating whether adversarial content actually survives web-crawl-based data curation pipelines and lands in the training set....