Kuba Rogut, deployed engineer at Turbopuffer, gave one of the more refreshingly direct takes on the “RAG is dead” meme that’s been making the rounds on X. His argument, in one sentence: RAG isn’t dead — what’s dead is the strawman version where RAG means “embed everything once, run a single vector lookup, dump it into the LLM context.” The actual frontier is hybrid, tool-rich retrieval, where embeddings, BM25, grep, glob, regex, and filters are all tools an agent can compose iteratively.
The strawman vs. the actual thing
The talk opens with the now-familiar X posts declaring RAG dead and observing that agentic file-system grep (à la Claude Code, Codex) is “all we need.” Kuba then puts up the Google Trends chart for “RAG” — interest spikes in 2023, plateaus through 2024, and then hits a new inflection point mid-2025. So much for dead.
His reframe:
- RAG = retrieval-augmented generation. Retrieval is not synonymous with vector search. It includes vector search, full-text/BM25, grep, glob, regex, structured filters.
- Agentic search = giving the agent a set of these tools. Not “grep the filesystem,” but “progressively, iteratively find and reason over context.”
The distinction matters because the X meme implies you can throw out the index and let Claude Code grep its way to comprehension — which works for a session but is wildly inefficient if repeated by every developer, every day.
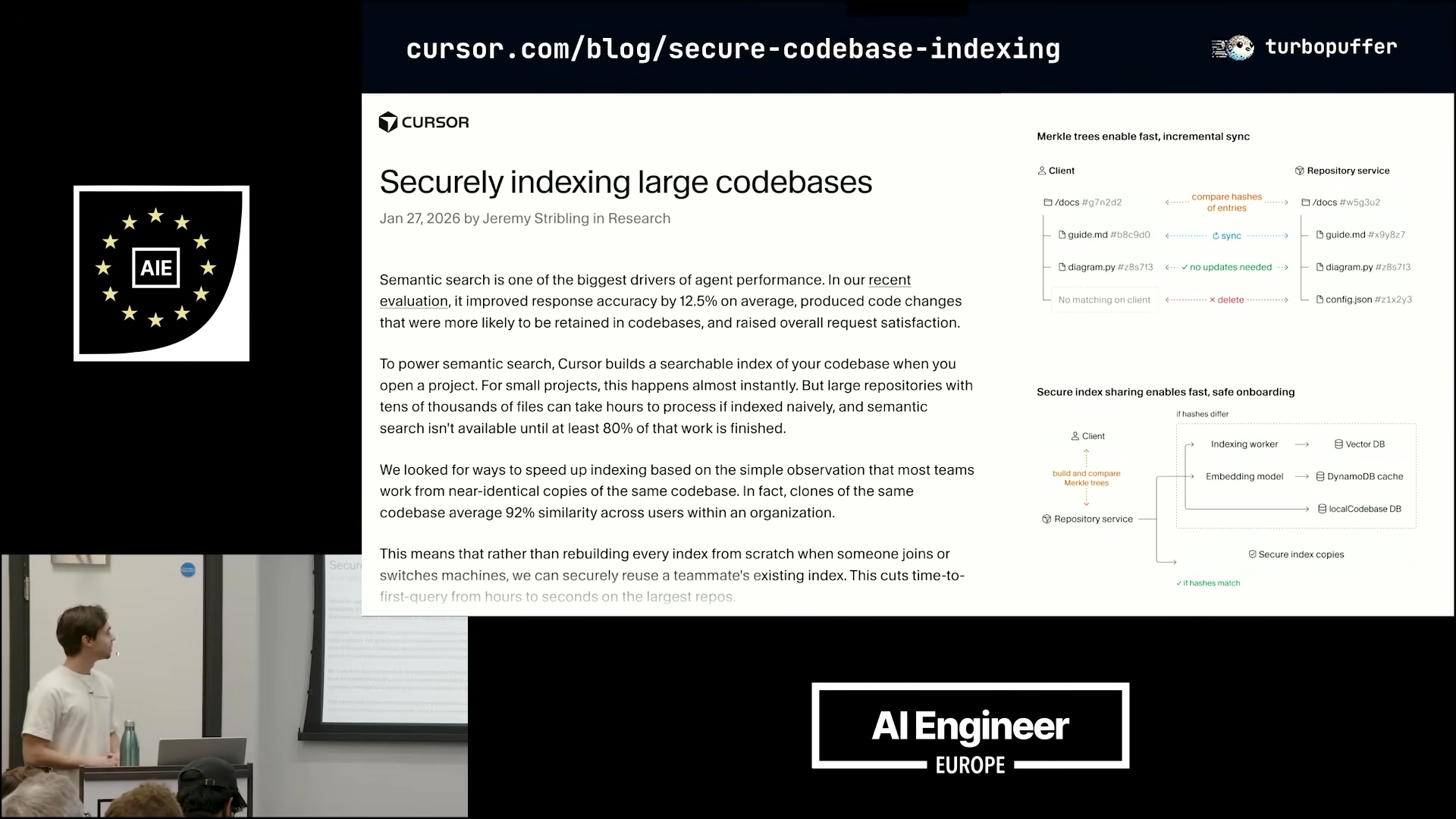
Case study: how Cursor indexes codebases
The most concrete part of the talk is Kuba’s walkthrough of Cursor’s published architecture, since Cursor is one of Turbopuffer’s earliest customers. When you open a new codebase or branch in Cursor:
- The repo is parsed, chunked, and embedded.
- The embeddings live in Turbopuffer, available for semantic search.
- Merkle trees are used to detect overlap with other developers’ indexed codebases on the same team — 99% of the time, 100 engineers are working on the same 1–2 repos, so re-chunking and re-embedding every time would be wasteful. Cursor copies forward the matching subtrees and only re-embeds files that have actually changed.
Does semantic search actually help?
Yes — and Cursor published the numbers. On their internal Cursor-bench benchmark, semantic search delivers an average 12.5–13.5% increase in answer accuracy across models. For the Composer model specifically (pre-Composer-2), the lift was ~24%. In production A/B tests, large-codebase users saw +2.6% code retention and −2.2% dissatisfied requests. Those headline numbers look small because semantic search isn’t invoked on every query — when you condition on the queries that actually use it, the impact is much larger.

Embeddings as cached compute
This is the core conceptual move of the talk. Compare two traces of “understand how metadata filtering works”:
- Claude Code style (per-session discovery). Grep → read → assess → repeat, every time. The same question asked by 10 developers on 10 different days re-derives the same understanding, burning thousands of tokens each time. Boris Cherney (Claude Code’s founding engineer) has publicly stated they tried local vector DBs in early iterations and they “just didn’t work out.”
- Cursor style (upfront indexing). A one-time cost to parse, chunk, and embed. At runtime, the agent issues a cheap semantic query and gets the relevant chunks back. Tokens saved, latency saved, money saved.
Kuba’s framing: embeddings are cached compute. Per-session grep-and-read is recompute. The right architecture is to amortize the expensive understanding step across all future agent sessions — which is exactly what an index is for. He notes that the Turbopuffer team itself has been switching from Claude Code to Cursor, mostly because the indexed semantic layer (plus Composer 2) makes it materially faster.

“You don’t need a trillion at once — you need the right million”
The talk closes on a Jeff Dean quote that captures the architectural point: even if context windows reach a trillion tokens, you still need staged, lightweight retrieval to narrow down to the right million. Big context isn’t a substitute for good retrieval; it changes the budget, not the principle.
“You don’t need a trillion at once. You need the right million.” — Jeff Dean
Turbopuffer’s customers, Kuba says, frequently embed trillions of tokens. The important work is still narrowing to the right 100K, the right 10K, the right million before it hits the model.

Key takeaways
- “RAG is dead” is a strawman. It conflates RAG with naive single-shot vector search. Actual retrieval combines vectors, BM25, grep, glob, regex, and filters.
- Agentic search ≠ grep. It’s a set of retrieval tools an agent composes iteratively.
- Embeddings are cached compute. Per-session filesystem grep recomputes understanding every time; an index amortizes it across all sessions.
- Semantic search measurably helps coding agents. Cursor’s published numbers: +12–13% answer accuracy on average, +24% for Composer, with real production-A/B retention lift.
- Merkle-tree dedup makes team-scale indexing cheap. Don’t re-embed what your teammates already embedded.
- Bigger context isn’t a substitute for retrieval. A trillion-token window still needs staged narrowing to the relevant million.
Source
- Talk: RAG is dead, right??
- Speaker: Kuba Rogut (Turbopuffer)
- Conference: AI Engineer
- Duration: ~11 min
- URL: https://www.youtube.com/watch?v=UM6sFg_jdlE