
This is the talk every backend engineer eventually watches. Jeff Dean walks Stanford’s distinguished lecture audience through eleven years of evolution in Google’s search infrastructure — from a single-machine inverted index in 1999 to a planet-scale system serving thousands of queries per second with sub-second updates. The value of the lecture isn’t the specific numbers; it’s how he reasons about each rewrite as a response to one constraint becoming unbearable, and the design patterns that survived across seven major rewrites.
Why search is a multiplicative problem

Dean opens with the metrics that grew between 1999 and 2010: index size is up roughly 1000×, queries per second are up another order of magnitude, per-document information is 3× richer, and — most surprisingly to him — update latency improved from “once a month if we were lucky” to seconds. The point is multiplicative: the cost of serving Google search is the product of all four axes, not the sum.
“The difficulty in engineering a retrieval system is in some sense the product of all these things, because you’re dealing with larger indices, you’re trying to handle more queries with more information per document, and you’re trying to update it more often and faster.”
Hardware gave them ~1000× compute headroom over the period. Everything else came from software rewrites — seven major ones, mostly invisible to users.
Encoding tricks that compound

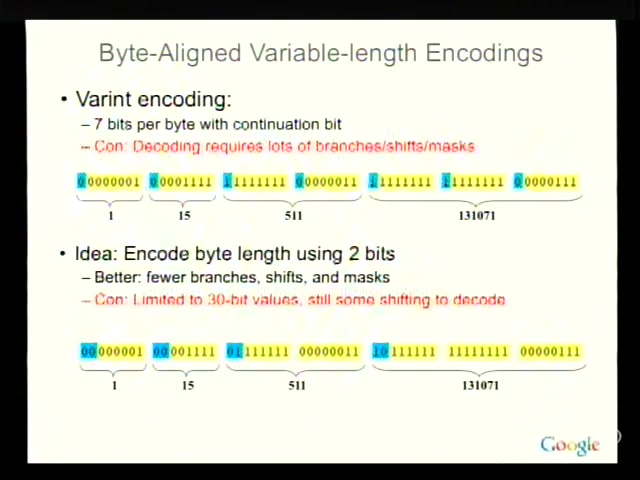
A long stretch of the talk is spent on how postings lists are encoded. The arithmetic matters: a single bit saved per doc-ID multiplied by trillions of postings is real money in disk, RAM, and bandwidth. Dean walks through delta encoding, variable-byte (continuation-bit) encoding, and finally group-varint, which packs four integers behind a single length-prefix byte to amortize branch costs on decode. The lesson generalizes: at scale, your encoding is your storage system.
When you can’t shard, randomize
By the mid-2000s, the index serving system had been re-sharded along multiple axes. Dean’s recurring move is to randomize document IDs across shards so that any query touches roughly the same number of postings on every shard — turning a worst-case latency problem into a tight tail by construction. Less famous than MapReduce or BigTable, but more broadly applicable: layout decisions are tail-latency decisions.
Treating machine failure as the API
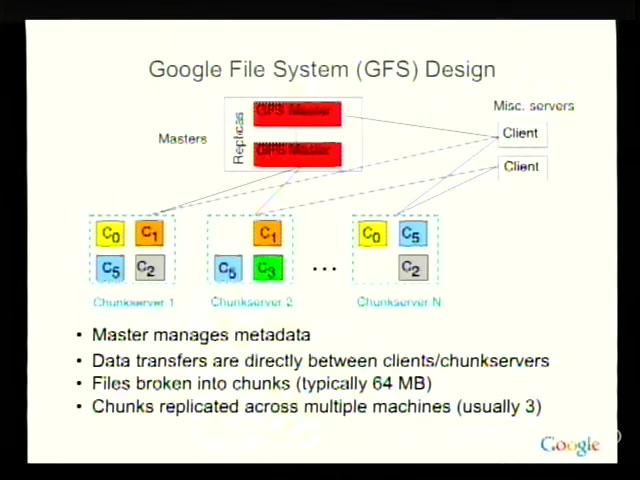
The middle of the talk is a compressed history of GFS, MapReduce, and BigTable, each framed as a response to a previous system’s pain point. GFS exists because, at Google’s scale, “the disk is unreliable” stops being an exceptional condition and becomes the steady state. MapReduce exists because writing yet another bespoke distributed batch job was burning out the smartest people at the company. BigTable exists because GFS files are too coarse for the actual access patterns of indexing, crawling, and ads.

The throughline: every abstraction is paid for by hiding one specific class of failure. MapReduce hides worker failure by making tasks re-runnable. BigTable hides storage failure by leaning on GFS replication. Spanner — discussed only at the very end — was the response to multi-datacenter deployment becoming a steady-state requirement rather than a fancy capability.
BigTable’s tree-shaped lookup

A small but lovely detail: BigTable’s tablet location lookup is a three-level tree (Chubby file → root tablet → metadata tablets → user tablets). Dean notes that a flat directory would have made the root a bottleneck — “obviously introducing a tree is a good idea” — and the audience gets to see a real production system using the same recursion trick they learned in algorithms class.
What kept Jeff Dean up at night (in 2010)

The Q&A is the most quotable part. Asked what infrastructure problems were keeping him awake, Dean didn’t say “scale” — he said complexity. The fleet of cross-datacenter tools — one for monitoring jobs, one for transferring files, one for replication — had each solved a slice of multi-datacenter deployment but together formed a maze. Spanner was the consolidating answer. The same complaint shows up word-for-word in the design docs of every multi-region database written in the decade since.
Key takeaways
- Re-derive the bottleneck before each rewrite. Seven Google search rewrites in eleven years, each motivated by a different dominant cost.
- Encoding is storage architecture at scale. Delta + varint + group-varint compound to make terabyte-class indices fit in cache lines.
- Randomize what you can’t shard cleanly. Random doc-ID sharding turns tail latency from a tuning problem into a structural one.
- Treat failure as the steady state, not the exception. GFS, MapReduce, BigTable each hide one specific failure class behind an API.
- Hierarchy beats flat lookup at every layer. BigTable’s three-level tablet tree is the same trick as DNS, mip-maps, and B-trees.
- Complexity compounds across multi-region deployments. Spanner is Google’s consolidation play, not just a database — every multi-region system since 2010 fights the same fight.
- Hardware gave 1000× compute; software gave everything else. The 1000× index growth, the seconds-to-fresh updates, the 5× latency win — those are all engineering, not Moore’s law.
Source
- Title: Building Software Systems at Google and Lessons Learned
- Speaker: Jeff Dean (Google Fellow)
- Venue: Stanford University CS Distinguished Lecture Series (E380), 2010
- Duration: 1h 22m
- URL: https://www.youtube.com/watch?v=modXC5IWTJI