Weekly Paper Notes — one of the top picks from the 2026-06-20 CS paper digest. Area: Databases / Systems.
Authors: Georg Kreuzmayr (TigerBeetle), Muhammad El-Hindi (TUM), Benjamin Wagner (Firebolt), Tobias Ziegler (TigerBeetle), Viktor Leis (TUM) arXiv: 2606.19969 · PDF
TL;DR
For two decades distributed database systems treated the network as an opaque, kernel-managed pipe and the kernel TCP stack was fast enough that this abstraction was free. It isn’t anymore. AWS Ethernet bandwidth has grown roughly 20× over the last decade (from ~10 Gbps to 200 Gbps on c7gn instances) while per-core CPU performance has barely doubled, and on a saturated 200 Gbps NIC the kernel TCP stack now consumes ~30 % of a c7gn core per direction. The performance bottleneck of a modern OLAP shuffle or a low-latency replicated KV-store is no longer the network — it’s the network stack.
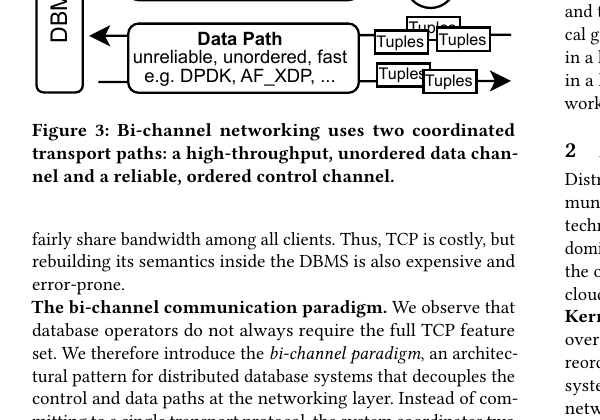
The paper proposes the bi-channel paradigm: stop trying to make one transport stack be both fast and reliable, and instead expose two coordinated channels to the database engine — a high-performance data path (user-space UDP via DPDK, AF_XDP, or similar) for the latency- and bandwidth-sensitive tuple movement, and a reliable, ordered control path (kernel TCP, with all its battle-tested guarantees) for coordination, acks, and recovery. The DBMS is the right layer to coordinate the two channels because it already knows which traffic is latency-critical and recoverable-at-the-operator-level (a shuffle batch can be re-issued) versus which traffic must not be lost or reordered (lease renewals, log entries, RPC return values).
Two end-to-end implementations validate the idea: a distributed shuffle that saturates 200 Gbps with just three CPU cores (compared to >10 with kernel TCP), and a replicated key-value store that pushes millions of messages per second per connection. The contribution isn’t a new network protocol — it’s a co-design pattern that gets the DBMS out from under the kernel-TCP overhead without forcing it to reimplement reliability from scratch.
What problem is the paper actually attacking?
The headline plot in the paper is one chart that explains the whole motivation. AWS Ethernet bandwidth on the largest network-optimized instances has tracked an aggressive growth curve: c3 (~10 Gbps, 2013) → c4 (~20 Gbps) → c5 (~25 Gbps) → c5n (100 Gbps) → c6gn (100 Gbps) → c7gn (~200 Gbps, 2023). Over the same interval, kernel TCP CPU overhead at saturation has risen from a small fraction of a core to dozens of percent of a core per direction — and a full-duplex shuffle pays it twice.
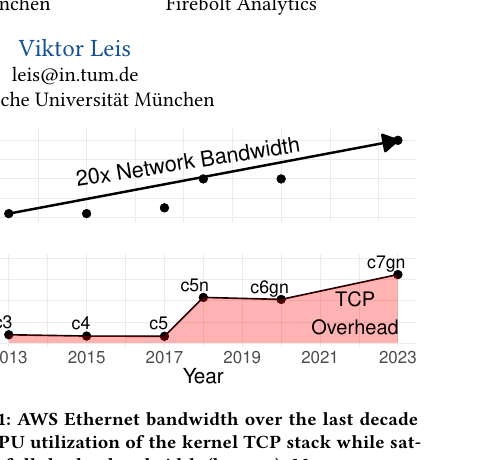 Source: Kreuzmayr et al. — arXiv:2606.19969, Figure 1.
Source: Kreuzmayr et al. — arXiv:2606.19969, Figure 1.
Measured precisely: kernel TCP on a 200 Gbps c7gn NIC needs ~2× more cycles/message than the theoretical NIC budget to fully utilize the link. At a 30 M messages/s NIC line rate, the budget is ~5,000 cycles/message; kernel TCP burns ~10,000. Result: the kernel stack is CPU-bound and achieves only ~50 % of nominal NIC utilization in a single-core test. The c7gn NIC outpaces what one core can pump through Linux’s network stack.
The community has known about this for years and the response has split into two unsatisfying camps:
- Kernel-bypass user-space stacks (DPDK, RDMA, AF_XDP, Seastar) deliver the throughput but cost you everything the kernel was doing for free: reliability, ordering, congestion control, NAT traversal, security policy. Building a production database on raw user-space UDP means reimplementing TCP, badly.
- Kernel stack improvements (io_uring, zero-copy send, kTLS) extract more throughput from kernel TCP but don’t change the asymptotic cost: kernel TCP at saturation is still spending order-of-magnitude more cycles than the NIC budget per message, and the gap is widening as NIC speeds outpace cores.
A third option — fully user-space TCP implementations (Seastar’s TCP, F-Stack, mTCP) — gets some of the throughput back but throws away the kernel’s ecosystem (monitoring, debugging, security hooks) and has historically had thin production deployment.
The paper’s observation is that this is a false trichotomy. The DBMS doesn’t have a single network workload — it has at least two. Bulk operator output (shuffle tuples, scan-side data) is bandwidth-dominated, latency-tolerant within a batch, and recoverable at the application level — a lost shuffle packet just gets re-requested. Coordination traffic (transaction acks, lease renewals, replica heartbeats, query plans) is small, latency-critical, and absolutely must not be lost or reordered. These two workloads have completely different transport requirements, and forcing them through one stack means choosing one set of compromises for both.
The mechanism: two channels, one DBMS-aware coordinator
Bi-channel networking splits the transport into:
- Data path — unreliable, unordered, fast. Implementation in the paper is user-space UDP over AF_XDP or DPDK, but the paradigm is implementation-agnostic. The DBMS knows the tuple stream can tolerate loss and reordering because the operator above it will handle reconstruction (e.g. a shuffle exchanges sequence numbers and re-requests missing chunks at batch granularity).
- Control path — reliable, ordered, slow. Kernel TCP is the obvious choice because it already has reliability, congestion control, security, and observability for free. The control path carries acknowledgments, retransmit requests, lease/heartbeat traffic, and the small coordination messages between operator instances.
The two channels are coordinated by the DBMS, not by the network stack. The shuffle operator decides which tuples are “in flight” on the data path; the control path acks at batch granularity and signals retransmission needs. The replicated KV-store puts the write path on the data channel and the consensus messages on the control channel.
Per-core throughput measurement makes the case starkly. The paper compares four configurations on a c7gn pair: kernel TCP (io_uring) ~5.8 Gbps/core, kernel UDP (io_uring) ~4.7 Gbps/core, user-space TCP (Seastar) ~7.6 Gbps/core, and user-space UDP (DPDK) ~190 Gbps/core — roughly 30× better than any reliability-providing stack. That number is what the data path of the bi-channel paradigm captures. The control path doesn’t need that throughput; it needs reliability, and the kernel TCP stack delivers it at cost the DBMS can afford because the control-path message rate is orders of magnitude lower than the data-path message rate.
Why infrastructure stays usable (the practical claim)
The paradigm’s main practical claim is that it preserves what the kernel was doing for you without paying the kernel’s cost on the hot path. Security policy, NAT, observability, congestion control, retry, and recovery all remain on the kernel TCP control path. The bypass-mode data path is restricted to traffic that is (a) intra-cluster between cooperating DBMS nodes (so the security boundary is the cluster, not the per-connection layer) and (b) recoverable at the operator level (so packet loss is a performance hit, not a correctness bug).
The paper is also careful about deployment realism: AF_XDP and io_uring are explicitly chosen because they’re already in mainstream Linux distributions and don’t require kernel modules from the vendor. DPDK is harder to deploy (CPU pinning, hugepages, dedicated NIC queues) but is the right choice when you can afford the operational overhead.
Results
Two end-to-end systems are evaluated:
- Distributed shuffle between c7gn.16xlarge nodes saturates 200 Gbps full-duplex with three CPU cores per host, vs. ~10+ cores for an equivalent kernel-TCP-only shuffle. This matches the ~30× per-core throughput advantage from the per-stack microbenchmark, applied to a real workload. The control path runs on kernel TCP and exchanges batch acks; latency on coordination messages is unchanged from the baseline.
- Replicated key-value store pushes millions of messages per second per connection, with consensus messages on the control channel and replication payload on the data channel. The bi-channel design keeps tail latency on coordination flat while raising achievable throughput by an order of magnitude over kernel-TCP-only.
Both results are in the regime where the kernel TCP baseline is out of cores before it’s out of bandwidth — i.e. where bi-channel is structurally necessary, not a marginal optimization.
Why this matters
The 200 Gbps NIC on c7gn is not the endpoint — 400 Gbps and 800 Gbps NICs are on cloud vendor roadmaps and per-core CPU performance is not going to keep up. Every database, message queue, and consensus system that today treats networking as an opaque kernel-managed pipe is going to hit this wall, and most of them already have it visible on their tail-latency curves.
What the bi-channel paradigm contributes is not a specific transport choice (DPDK vs AF_XDP vs RDMA vs SmartNIC offload) but the separation principle: the workload above the network has at least two transport profiles and the system should expose both, with the DBMS as the coordinator. Once the principle is accepted, the implementation can pick whichever data-path bypass technology fits the deployment, and can upgrade it independently of the control path.
The next obvious step is integration with DPU / SmartNIC offload: the data path can move into NIC firmware while the control path stays on the host kernel, pushing per-host CPU cost on bulk shuffle toward zero. The paper hints at this without committing to it.
The other follow-up worth watching is the OLTP case. The paper’s examples are bulk shuffle (clearly bandwidth-bound) and replicated KV (interesting but already heavily studied). The harder question is whether transaction-processing workloads, where individual messages are small and latency dominates, can benefit from the same split — or whether the message rate is low enough that kernel TCP overhead never dominates.
Read alongside
- DPDK and AF_XDP documentation — the candidate data-path implementations.
- Seastar (ScyllaDB) and mTCP — prior user-space TCP attempts the paper benchmarks against.
- eRPC (Kalia, Kaminsky, Andersen, NSDI 2019) — single-channel user-space RPC over UDP; bi-channel can be read as a generalization that adds a control plane.
- NetCache / NetChain — earlier in-network co-design work; bi-channel takes the co-design idea but keeps the work on commodity NICs.
- Junction / Caladan (MIT) — kernel-bypass runtimes for tail-latency workloads.
- TigerBeetle architecture posts — the authors’ production OLTP system motivates the design.
Links
📄 arXiv abstract · 📄 PDF
Part of the Weekly CS Paper Digest series. Summary written from a close read of the preprint; figures cropped from the arXiv PDF and reproduced here under fair use for educational commentary.