
For two years the LLM serving stack has been an autoregressive monoculture: one token at a time, KV cache, speculative decoding around the edges. Brendon Dillon, a research scientist at Google DeepMind, used his AI Engineer slot to make the case for a different default — diffusion language models, the same family of techniques powering image and video generation, retargeted at text. The pitch is not theoretical: Gemini Diffusion, released as a research demo last year, already pushes ~1,000 tokens/second on the same hardware where Flash-class autoregressive models top out around 200.
The mechanics: noise → text instead of left-to-right
A diffusion text model is trained the same way as a diffusion image model. Take a clean sequence, corrupt it (replace random tokens with random tokens, or mask them), and train a network to denoise. At inference, start from pure noise across the entire output buffer and iteratively refine — all positions in parallel, each step.

The contrast with autoregressive generation is the whole point. An AR model emits token 1, conditions on it to emit token 2, and so on — strictly sequential, strictly left-to-right. A diffusion model sees the full context and the full noisy output, and lets the network choose which positions to commit first. The order isn’t fixed by the architecture.
Why it’s faster: it’s a hardware story, not a math story
The accuracy of diffusion text models is roughly comparable to AR at matched parameter counts. The win is throughput per request.
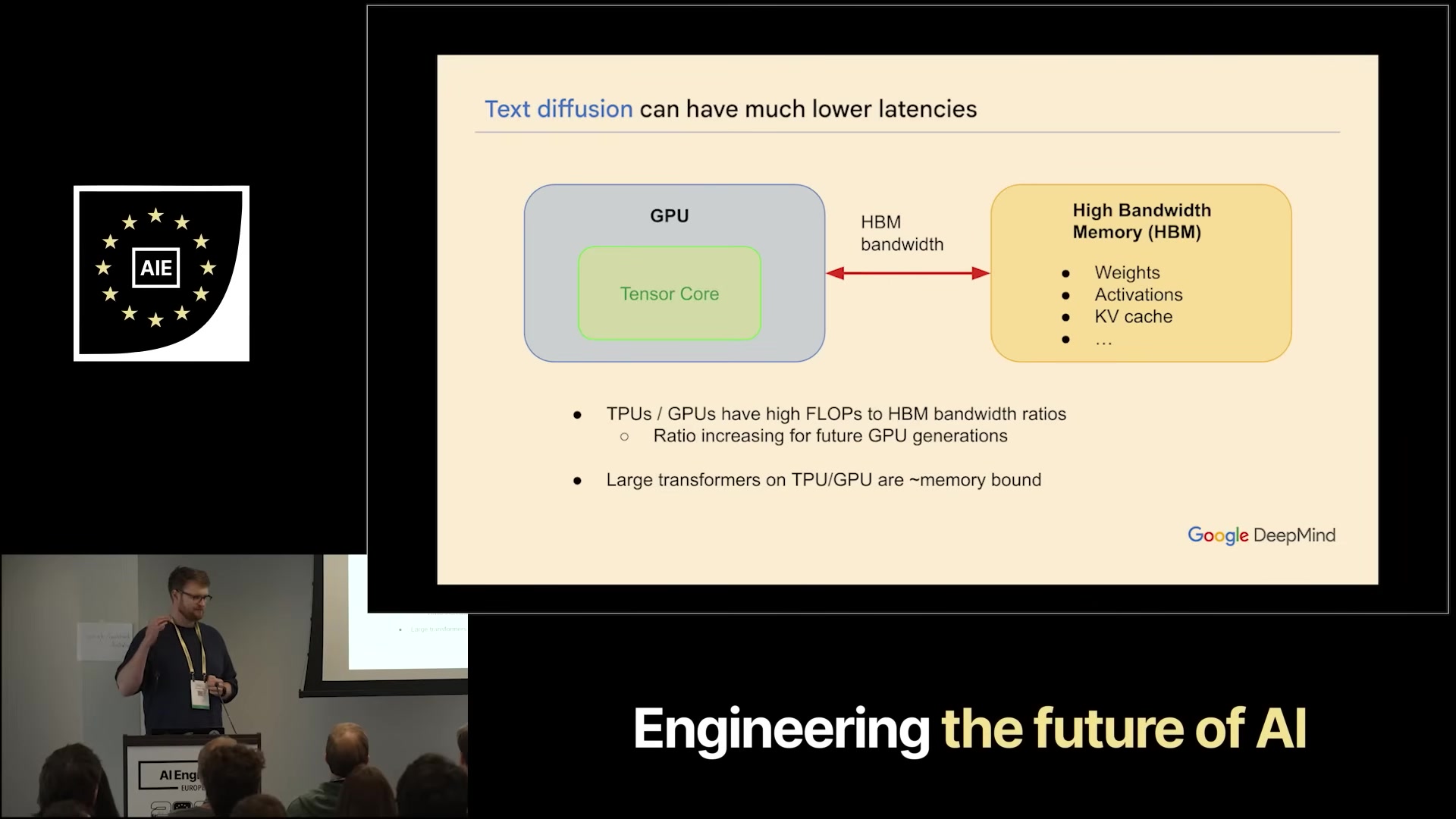
Modern accelerators (TPUs, H100s) are dramatically over-provisioned on FLOPs relative to memory bandwidth. An AR forward pass reads the entire model’s weights from HBM to generate one token. That’s the bottleneck — you’re bandwidth-bound, the tensor cores sit idle. Diffusion runs one forward pass and refines the whole sequence at once, so each HBM round-trip produces hundreds of tokens worth of work. The tensor cores actually get fed.
This is also why diffusion’s throughput advantage shrinks at very small batch sizes and grows as outputs get longer — the same arithmetic-intensity argument that drives speculative decoding, but structural rather than bolted on.
Live demo: parallel refinement in action
Dillon showed the model answering “what is √81 × 2/3?” — the diffusion output appears as a wash of garbled tokens that snap into a coherent answer over ~10 refinement steps, rather than streaming left-to-right.
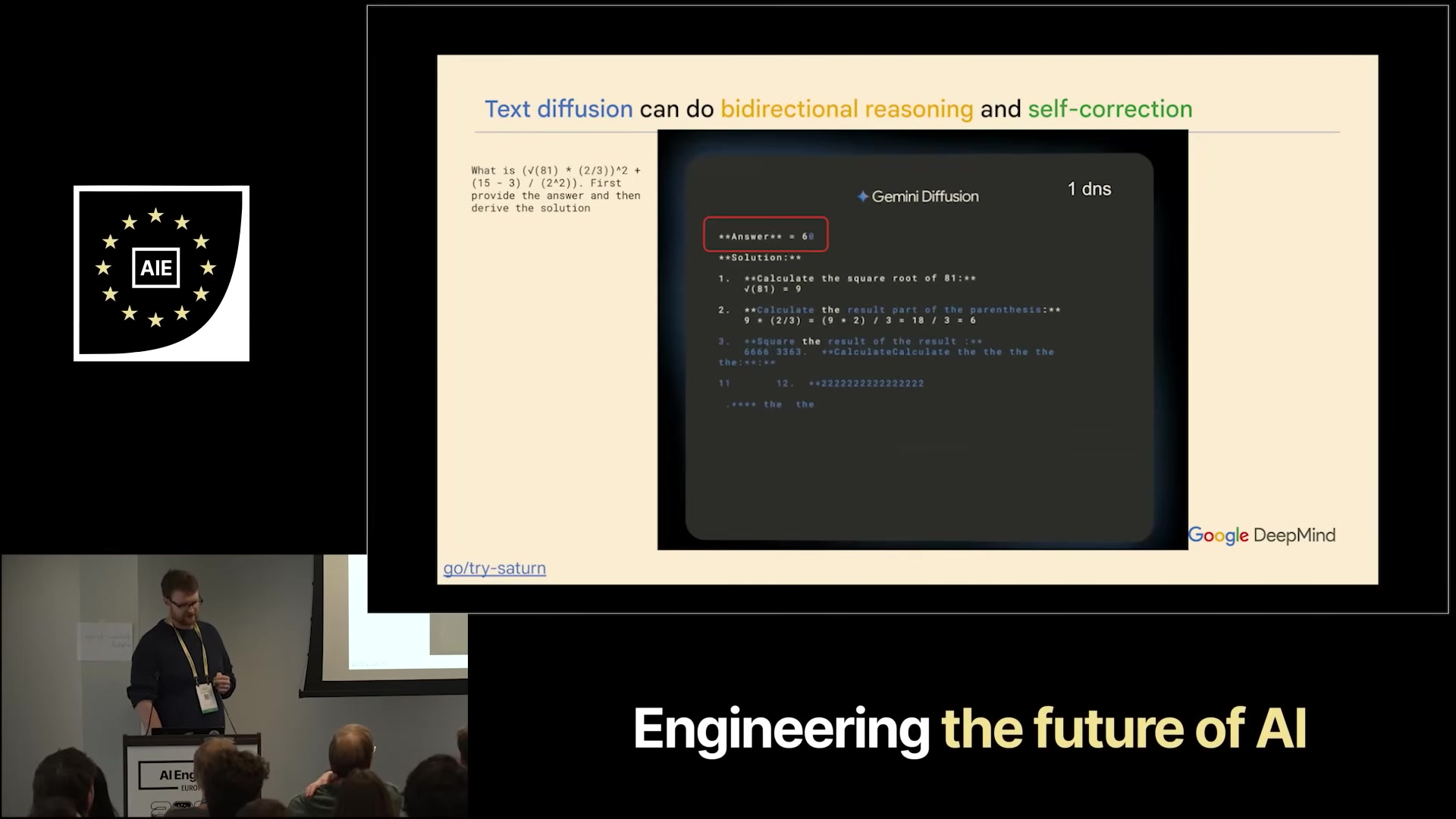
The visual is striking because it makes the parallelism legible: the model commits high-confidence positions first (often the answer digits) and fills structural words around them, instead of having to commit to “The answer is” before it has decided what the answer is.
Where it shines, where it doesn’t
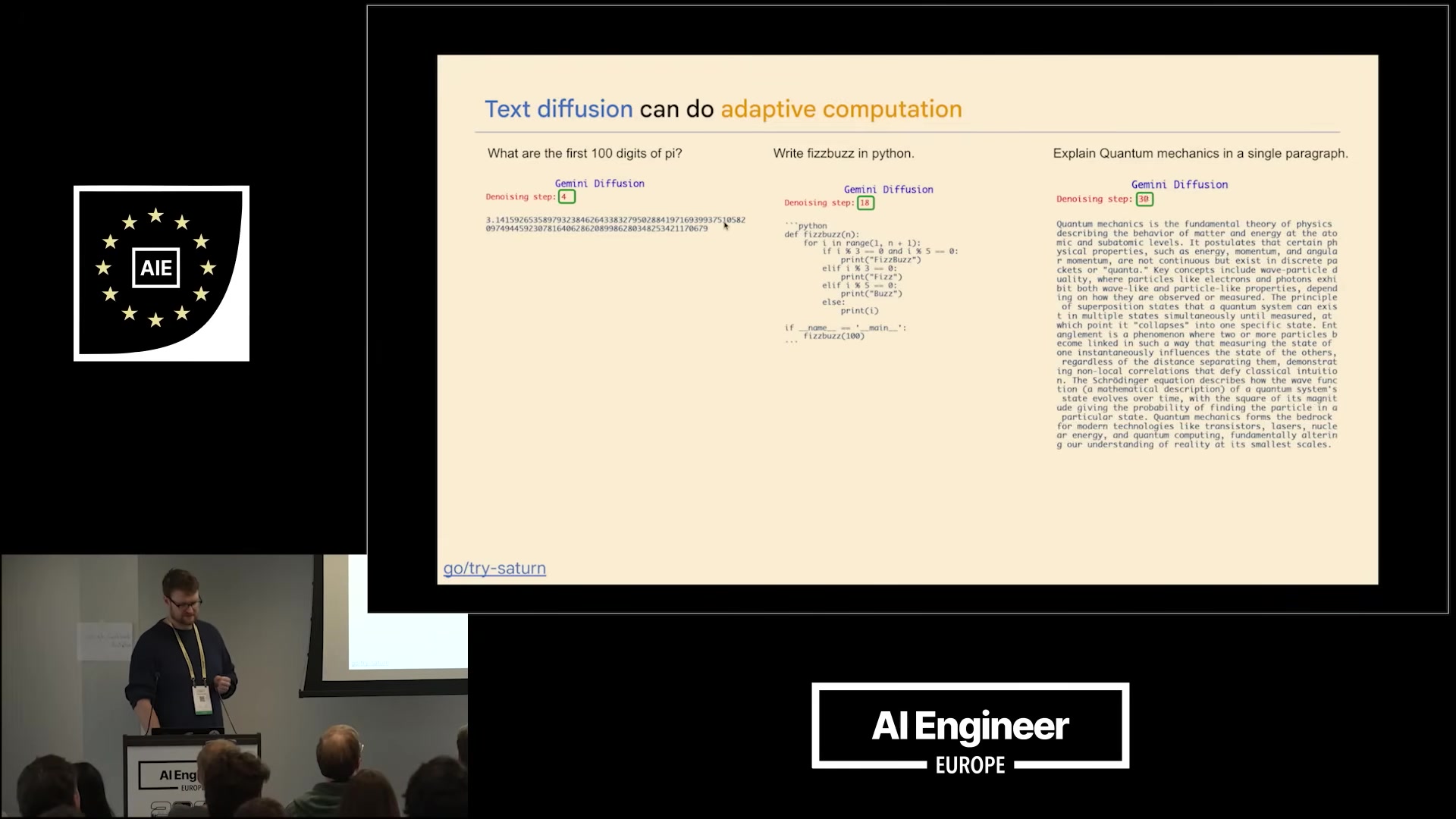
Wins:
- Latency for long outputs: 100 tokens of pi digits comes back in a handful of refinement steps rather than 100 sequential forward passes.
- Infilling / structured edits: because the model sees the whole sequence, asking it to fill the middle paragraph of a three-paragraph essay is native, not a fine-tuning trick.
- Self-correction within a step: a diffusion step can revise an earlier token if a later one suggests the earlier one was wrong. AR can’t go back.
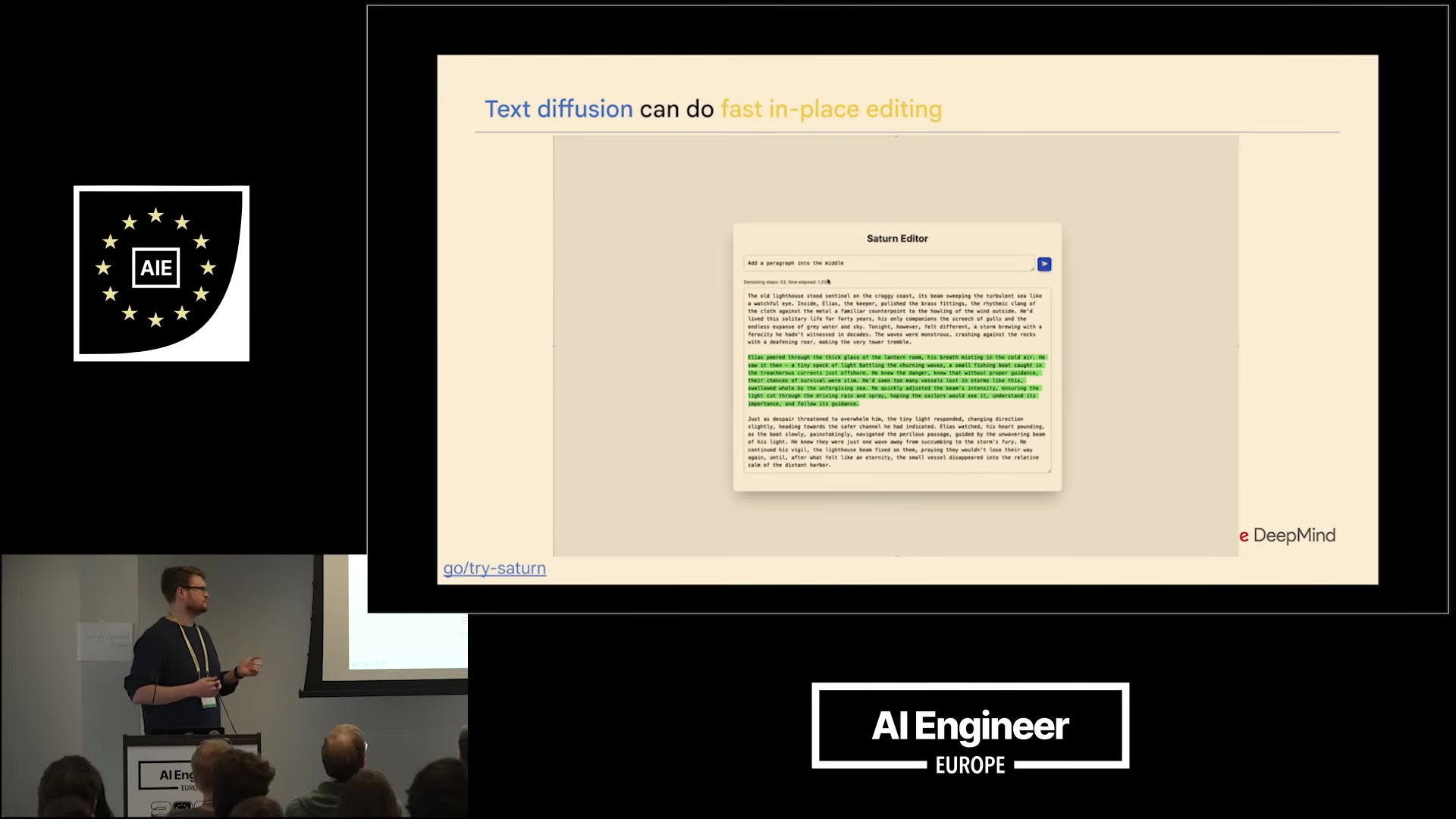
Losses:
- Per-query throughput at high batch sizes is worse: an AR server amortizes one model load over many concurrent streams via batched decoding. Diffusion’s wins are biggest when latency, not aggregate tokens-per-dollar, is the constraint.
- Tooling gap: KV-cache tricks, speculative decoding, prefix caching — none of them transfer. The serving stack has to be rewritten.
- Quality at the extreme tail: on the hardest reasoning benchmarks the gap to frontier AR models is still real, though closing.

Key takeaways
- Diffusion text models are real, not a research toy — Gemini Diffusion is the existence proof.
- The speedup is a hardware-utilization argument, not a sample-efficiency one: AR forward passes are memory-bandwidth-bound and waste FLOPs.
- Infilling and revision are native, which makes diffusion a natural fit for code editing, structured generation, and constrained outputs.
- The serving stack does not transfer. KV cache, speculative decoding, and continuous batching all assume AR. Building diffusion-native inference is open territory.
- Quality is competitive at matched scale but the frontier autoregressive models still lead on the hardest reasoning evals.
- For latency-sensitive AI Engineering workloads — voice agents, IDE autocomplete, structured-JSON tool use — diffusion is the most credible 5–10× speed-up on the horizon.
- Watch the bigger Gemini Diffusion releases Dillon hinted at: scaling laws for diffusion text are still being mapped, and the early signal is that they hold.
Source
- Title: Text Diffusion
- Speaker: Brendon Dillon, Research Scientist, Google DeepMind
- Venue: AI Engineer (June 2026)
- Duration: 28 minutes
- Link: https://www.youtube.com/watch?v=r305-aQTaU0