Weekly Video Notes — a short article distilling one talk from the weekly digest. Source video and key frames are embedded throughout.
LangChain’s annual conference Interrupt 2026 opened with co-founder Harrison Chase laying out a thesis the company has been quietly building toward for two years: agents aren’t software, and you can’t ship them with a software lifecycle. What follows are the key ideas from the keynote, plus the half-dozen product launches LangChain announced to back the thesis.
Why agents need their own lifecycle
Chase opened by naming the two properties that make agent engineering structurally different from traditional software:
- The input space is infinite. Natural language has unbounded dimensions, and increasingly the input includes images, audio, and video.
- The output space is non-deterministic and prompt-sensitive. Even a “deterministic” LLM is fragile to small prompt changes.
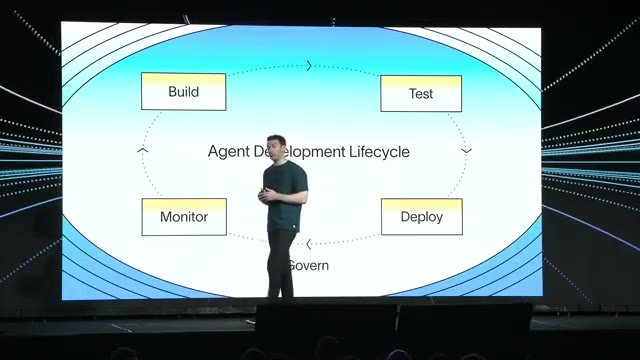
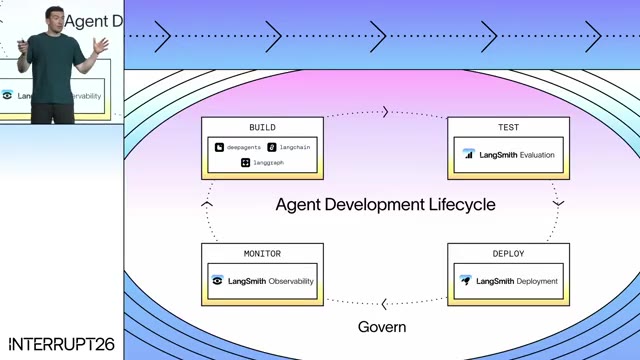
You can’t predict how the combined system will behave before users touch it. The pattern that consistently works, he argued, is ship early and iterate quickly — and that iteration cadence is what he calls the Agent Development Lifecycle (ADL): Build → Test → Deploy → Monitor, parallel to the software lifecycle but with different steps at each stage.
“The mastery of this lifecycle, whether people call it that or not, is really what people are doing when they’re building organizations and tools to ship agents.”
The talk then walked the four phases, attaching a launch to each.
1. Build — Deep Agents 0.6
The core of an agent has been stable since the original LangChain AgentExecutor: an LLM in a loop calling tools. What’s changed is the harness around that loop.

Deep Agents is LangChain’s harness. Beyond the basic loop, it bundles:
- Execution environment — a spectrum from a virtual file system (a DB exposed as files; cheap, multi-tenant) to full sandboxed code execution.
- Context management — short-term memory via summarization, context offloading for large tool calls, automatic prompt caching.
- Steering / human-in-the-loop — long-horizon agents are not fully autonomous; the harness provides interrupt and intervention primitives.
- Delegation — primitives for spawning planning agents or sub-agents and routing their outputs back.
The 0.6 release lands three things, each tied to a market trend:
| Trend | Launch |
|---|---|
| Open models are catching up (DeepSeek V4 was cited as on-par on many tasks) and frontier costs are rising | Native support for GLM-5, DeepSeek, Nemotron + best-in-class integrations with Fireworks, Baseten, NVIDIA + a new open-source reference Deep Agents Code coding agent |
| Execution environment is a sliding scale and the middle was empty | CodeInterpreter, a QuickJS-based JS runtime — a lightweight middle ground between virtual FS and full Docker sandbox; cheap to deploy multi-tenant |
| UIs for streaming agent events are still painful | New streaming protocol + 4 front-end SDKs + partnerships with CopilotKit, Assistant UI, Vercel |
2. Test — LangSmith Evaluations
Testing agents looks unlike testing software: you build datasets (reference inputs/outputs or criteria), define metrics (correctness, hallucination rate, custom domain rules), run the agent across the dataset, and produce experiments you can either hill-climb against or use as regression guards.
LangSmith has been building this layer for two years. Chase deferred the new launches in this area to a later section of the keynote.
3. Deploy — LangSmith Deployments, Sandboxes, and Context Hub
Going from a local dev loop to production introduces a familiar but newly-shaped set of problems: multi-user state (env vars, per-user memory), auth, and durable execution that survives crashes.
Three production launches:
LangSmith Deployments (shipped a year ago) — ~30 API endpoints covering streaming, HITL, auth; one standard deployment pattern; already serving 100M+ agent runs for customers including Workday, Cisco, Etsy, Podium, ByteDance.
LangSmith Sandboxes (GA today) — sub-second sandbox spin-up with persistence, snapshots, and forks. The headline feature is an auth proxy that sits outside the sandbox and injects API keys into outbound requests, so the LLM never sees the credentials it’s using and can’t leak them via prompt injection. Framework-agnostic SDK — works with Deep Agents or anything else, in training (RL) or production. Monday uses it for their Sidekick assistant.
LangSmith Context Hub — versioned storage for the new shape of agent context: agents.md files, skills, and Karpathy-style LLM-generated wikis (condensed knowledge in markdown). Tags, comments, versioning. You can pull context down into your coding CLI, mount it into Deep Agents as a virtual FS, or use it from any harness.
The Context Hub announcement came with a notable open-standards commitment: LangChain is partnering with Redis, Elastic, Mongo, and Pinecone to turn this into an open memory standard. Chase’s framing: “Memory should not be locked in to an LLM, to a framework, or to a platform.”
4. Monitor — Tracing, Dashboards, Online Evals, and the LLM Gateway
The monitor phase is where LangSmith’s tracing has lived since day one — full step-by-step traces of agent runs, cost/latency dashboards, LLM-as-judge online evals, captured user feedback.
The new piece is the LangSmith LLM Gateway (beta), a proxy between your agents and their LLM providers that adds:
- Spend limits and per-user/per-agent cost visibility (the “no surprise bills” pitch as governance becomes the next pain after you ship 10+ agents).
- PII and secret detection guardrails on the request stream.
- Coding-agent integrations — explicitly called out because coding agents are where most of the spend lives.
- Everything is automatically traced into LangSmith.
The unifier: Managed Deep Agents
To compress all of the above into a single product surface, LangChain announced Managed Deep Agents (private preview): one API that wires Deep Agents (harness) + LangSmith Deployments (runtime) + Context Hub (instructions/memory) + LangSmith Sandboxes (execution) + MCPs (tools, including via partners like Arcade) + the new streaming protocol (UI integration).
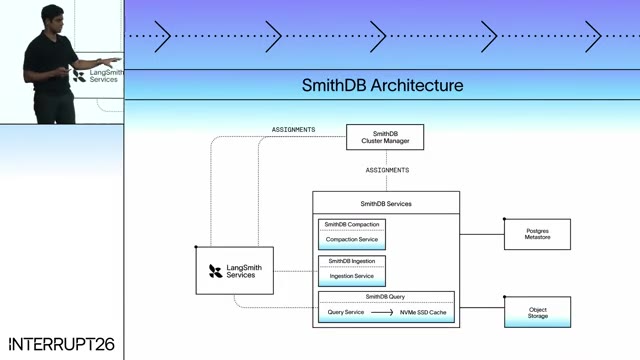
SmithDB — a database purpose-built for agent traces
Co-founder and CTO Ankush Gola then took the stage to introduce the largest infrastructure announcement of the day: SmithDB.
The motivation is that agent traces break the assumptions of every traditional observability backend:
- Deeply nested — thousands or tens of thousands of intermediate steps per trace.
- Large and unbounded payloads — driven by larger context windows and longer time horizons. LangSmith’s measured P50 payload grew from 6 KB → 37 KB in two years. P99 went from 364 KB → 12 MB. One customer sent 50 TB of trace data on a single day.
- Multimodal — images and voice are now common in customer-support traces.
- Volume — one customer’s weekly trace count grew from a handful in dev to 150+ million in production.
- Unique access patterns — full-text search across nested span content, plus top-K + filter queries scoped by time, metadata, tags, latency.
One illustrative data point on trace size: an internal go-to-market agent built on Deep Agents produced a single trace encoding 8.1 million tokens.
Architecture
- Object storage at the foundation — cheap, effectively infinite, and gives compute/storage separation so services can scale elastically without resharding. Also makes self-hosting feasible for residency-strict customers.
- Cluster manager for assignment and sticky routing (preserves cache locality and lets ingestion batch efficiently).
- Ingestion service durably writes batches to object storage; files are registered in a Postgres metastore.
- Query path figures out which files a query needs, pulls them from object storage, scans them. SSD + memory caching minimizes round trips.
- Compaction service reshapes files for query efficiency.
Tech stack
- Written in Rust.
- Apache DataFusion as the extensible query engine.
- Vortex as the file format — extensible, lets them pick per-column encodings and chunking strategies.
- Custom inverted index for full-text search, custom query planning, custom storage layouts.
Specific engineering challenges Ankush called out
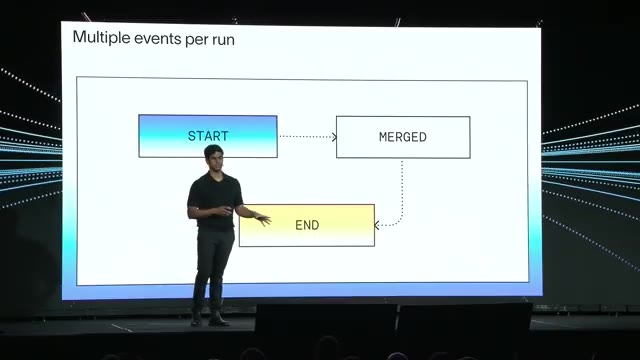
- Distributed spans. Agents run for hours; start and end events can arrive far apart. Merging them efficiently at query and compaction time is non-trivial.
- Top-K queries on object storage. Naive fan-out-scan-merge is expensive on object storage. They built a time-window-based custom execution plan for top-K + order-by + limit queries.
- Leading-edge data freshness. They buffer recently ingested data in memory and SSD on the ingestion service even after it’s been flushed to object storage, so query traffic for the newest data doesn’t have to fetch many small files.
Results
End-to-end LangSmith workloads run 6×–15× faster than the previous stack. SmithDB now backs the tracing projects page across all of LangSmith US Cloud; self-hosted and global cloud are coming. Early adopters: Clay and Vanta.
Ankush closed with a Jeff Dean quote that hints at why this matters for the future: as agents start operating at multiples of human speed, your tools become an Amdahl-style bottleneck for the entire system. Increasingly, the user of an observability platform is not a human — it’s another agent.
LangSmith Engine — an agent for the iteration flywheel
Tracing visibility is table stakes. The actual loop — find issues among millions of traces, understand them in long execution logs, fix them in the right place (prompt? code? tool?), and prevent regressions — is still hard. Often it feels like whack-a-mole.

LangChain’s answer: LangSmith Engine (public beta), an ambient, proactive, action-taking agent that:
- Sits on top of your traces and scans them on a schedule.
- Detects issues, prioritizes them, and backs every finding with concrete trace evidence.
- Suggests resolutions across the full lifecycle — code changes (if hooked to your GitHub repo), new dataset entries to guard against regressions, prompt or Context Hub edits, and new online evals to track recurrence.
- Has already, in early-access deployments, “dramatically reduced time to detection and time to triage.”
This is the closest thing in the keynote to a thesis statement for where LangChain thinks the next year goes: the engineer working on agents will themselves be working with an agent that closes the ADL loop.
Key takeaways
- Agents need their own SDLC. Build → Test → Deploy → Monitor, with iteration speed as the dominant variable. Ship early; the input/output spaces are too large to predict offline.
- Harness > model. Most of the production-readiness of a “good agent” lives in the harness around the LLM loop: execution environment, context management, steering, delegation. Deep Agents is LangChain’s bet on this surface.
- Open weights are now in scope. DeepSeek V4 and similar models forced first-class support for open-model providers (Fireworks, Baseten, NVIDIA) into the harness.
- Memory and context want to be open. Context Hub ships, but LangChain is explicitly working with Redis, Elastic, Mongo, and Pinecone toward an open memory standard for agents.
- Agent observability is a distinct data-infrastructure problem. Traditional logging/metrics stacks lose. SmithDB — Rust + DataFusion + Vortex on object storage — is LangSmith’s specialized answer, with 6–15× speedups in production.
- Agents will use your tools too. Once agents operate at multiples of human speed, slow tools cap the whole pipeline. Observability and gateway tools are increasingly built for agent UX, not human UX.
- Governance is the next pain point. Once you run 10+ agents, the LLM Gateway pattern (spend limits, PII/secret guardrails, central tracing) becomes table stakes.
- The lifecycle itself becomes agentic. LangSmith Engine sits on traces, finds and triages issues, and proposes fixes across the lifecycle — making the iteration flywheel itself the product.
Source
📺 The Agent Development Lifecycle: Build, Test, Deploy, Monitor — Harrison Chase & Ankush Gola, LangChain Interrupt 2026 (~45 min)