Weekly Video Notes — a short article distilling one talk from the weekly digest. Source video and key frames are embedded throughout.
What’s better than one GPT-5.5 Pi coding agent? Two GPT-5.5 Pi coding agents that can actually talk to each other. That’s the opening provocation of IndyDevDan’s latest video, and it leads into a deceptively simple shift in multi-agent design: drop the orchestrator, give every agent a two-way communication channel to every other agent, and let the best information win.
The pattern in one screen
Most multi-agent systems today are top-down. A “lead” agent (often Claude Code in orchestrator mode, or a LangGraph-style planner) plans, delegates to sub-agents, collects their results, and decides what to do next. Information flows one direction even when the response comes back. There is exactly one decision-maker.
Dan’s pitch: that’s a hierarchy, and ideas die in hierarchies. Replace it with a flat pool where every agent can list_agents, send_command, and await_response against every other agent. No parents, no children — just coworkers on a shared chat channel.

The agents can run on the same machine, on different machines on your LAN, or anywhere reachable by a small HTTP server. Each one is just a terminal-resident Pi agent (Dan’s preferred harness — an open, customizable alternative to Claude Code / Codex / Gemini CLI) with one extension loaded.
The motivating demo: prod ↔ dev with PII redaction
The first walkthrough is a workflow that exists in every real engineering shop and is genuinely hard to do safely with a single agent:
A Pro-tier user is getting locked out of Pro features in production. Reproduce the bug on a developer machine using the affected slice of production data — without leaking any PII.
Dan boots two agents:
prodon his Mac Mini production box. Prompt: you are the prod gatekeeper, you have a seeded production DB, you have a teammate on the network, you must not expose PII to any other agent.devon his M5 MacBook Pro. Prompt: bring the affected slice from production over with PII stripped into your local dev DB so an engineer can reproduce the issue locally.
The dev agent uses list_agents, sees prod on the network, sends it a prompt, gets back a message ID, and awaits. The prod agent — knowing its own constraints — pulls the affected rows, applies redactions, and ships only the sanitized slice back. The two go back and forth until the dev box has a reproducible repro and both context windows independently confirm “PII safe, issue reproduced.”
The interesting part isn’t the demo, it’s the trust boundary. Because each agent has its own prompt and its own context window, the prod agent’s redaction policy never has to be re-injected into the dev agent’s context — it’s enforced on the prod side by the prod agent’s system prompt. Compromise the dev agent and you still can’t extract PII through it.
Why peer-to-peer beats top-down (sometimes)
Dan spends a chunk of the talk arguing this from first principles — information hierarchy. In a traditional org, objectives travel downstream and the best ground-truth information is at the bottom with the engineers, where it often gets stuck because of titles, politics, or just communication latency. Flat structures (his examples: Nvidia, most startups) outperform because valuable information beats titles.
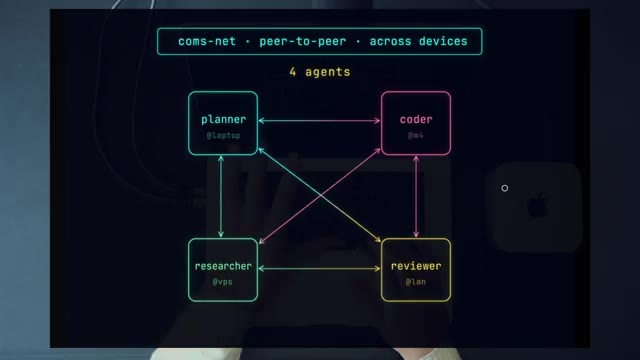
He’s careful to flag the limits of the analogy. The agentic upside isn’t moral — it’s mechanical:
- Bidirectional flow — there’s no single context that has to absorb everything before forwarding it. Both sides can ask clarifying questions.
- No information loss — a delegating orchestrator paraphrases. Two peers don’t have to.
- Cross-device by default — once the comms layer is a tiny HTTP server, “the network” can include your Mac Mini, your laptop, an EU production VM, a cloud sandbox, anything.
- Specialized, focused context windows — each agent is loaded only with what it needs.
That last point becomes the second demo’s main thread.
Demo two: building a feature-parity skill via two specialized agents
Setup: Dan has an existing E2B agent-sandbox skill he uses to spin up sandboxes from inside a Pi agent. He wants an exe.dev equivalent — same surface area, mapped onto exe.dev’s persistent VM primitives, plus a feature-parity doc that flags anything that doesn’t translate one-to-one.
He boots two agents in a fresh comms pool:
- E2B agent (GPT-5.5) — loaded with the existing E2B skill, prompt: you’re the E2B expert, your teammate is exe.dev, answer their questions. It first generates a compressed feature inventory file as a reference for itself.
- exe.dev agent (Opus 4.7) — prompt: you’re the driver. There is no exe.dev skill yet. Build one. Reference target is the E2B skill. Your teammate will answer questions.
The agents trade messages, validate each other’s claims (Dan calls out parallels with his earlier verifier-agent pattern), surface 10 corrections to the parity doc in a single exchange, and converge on a working skill plus a parity document. Each context window stays around 20% — neither agent has to load both APIs.
Dan’s framing: this is why peer-to-peer matters beyond demos. Once you accept that the agent ecosystem is going to be a hundred swappable services (sandboxes, vector stores, cloud DBs, harnesses), this pattern — one specialized agent per service, peers comparing notes — is how you build and maintain integrations at scale without one giant context window melting.
He also reiterates the principle this is built on:
A focused agent is a performant agent. The art of context engineering is not getting all the right things — it’s getting just the right things.
The mechanism: four tools, no magic
The implementation is genuinely small. Dan shows the extension’s tool list:

list_agents— see who’s on the network.send_command(agent, prompt)— returns a message ID.await_response(message_id)— blocking wait.poll_response(message_id)— non-blocking poll.
He ships two versions of the extension:
comms— single-device, in-process message bus.comms-net— a tiny Bun HTTP server that exposesconnect,get_messages,list_agents,process_events, etc., so agents on different boxes can join the same pool.
Both will land in his open Pi vs. Claude Code repo. The whole point of showing the code is that it’s hackable — Dan’s advice: read and adapt. Throw your agents at it. Always understand the code.
Pros and cons
A talk that only sells the upside is a talk you shouldn’t trust. Dan ends with both columns.
Pros
- It’s just an agent + extension. No sub-agent lifecycle, no resume flags, no orchestrator framework. A terminal session per agent.
- End-to-end customizable. Because the harness is yours, you control comms, prompts, context, tools — the whole loop.
- Flat by construction. Two-way, no information loss, no single agent to rule them all.
- Primitive over composition. You still can assemble these peers into an orchestrator-style topology when you want one. Going the other direction (peeling peers out of a baked-in orchestrator) is much harder.
Cons
- You have to build (or borrow) it. Pi extensions aren’t a product you rent.
- Loops are easy with sloppy prompts. Two agents can happily ping-pong until your token budget evaporates. You need clear end states.
- Cost scales linearly with agent count and roughly quadratically with chatter. There’s a sweet spot — Dunbar’s number for agents, more or less. Trim aggressively.
- It’s tempting to fall back into orchestrator-thinking. If you actually need a planner-on-top, just build that. Use peer-to-peer where peer-to-peer wins.
Why this is a “Pi agent” video, not a “Claude Code” video
Dan is explicit: you can’t easily build this on top of Claude Code, Codex, Gemini CLI, or open code-tools today, because those are rented harnesses. They decide what extensions you can install, what the tool loop looks like, and what an “agent” even is. The reason he keeps reaching for the Pi coding agent — even while still using Claude Code daily — is that owning the harness is what lets him explore patterns that aren’t on anybody’s roadmap yet.
The tool you use limits what you believe is possible.
His estimate, half-joking: only ~1% of the state space of agentic engineering has been explored. Most of the rest will require the freedom to mess with the loop itself.
Key takeaways
- Sub-agent delegation is top-down. Peer-to-peer is flat. They’re complementary, not substitutes — but the flat pattern is the under-explored one.
- Bidirectional comms = no information loss. Two specialized agents bouncing questions back and forth preserves nuance that any “summarize and forward” orchestrator would lose.
- Trust boundaries become natural. A prod gatekeeper agent with a strict system prompt is a real PII firewall — its context never has to leak into the dev side.
- Context engineering wins again. Two agents at 20% of a 1M window beat one agent at 40% trying to juggle both APIs. Focused context = performant agent.
- The primitive is tiny. Four tools (
list / send / await / poll) and a Bun server. The leverage is in the pattern, not the code. - Watch for loops, costs, and over-scaling. Three to a handful of peers is usually plenty. Trim, give them end states, and don’t reinvent orchestration when orchestration is what you actually want.
- Owning your harness is the meta-point. Patterns like Pi-to-Pi simply aren’t reachable from inside a rented agent CLI. If you’re serious about agentic engineering, hack on the harness.
Source
📺 Pi to Pi: Two-Way Agent Orchestration with the Pi Coding Agent — IndyDevDan (~35 min)