
Weekly Video Notes — a short article distilling one talk from the weekly digest. Source video and key frames are embedded throughout.
Ron Minsky opens his talk with a self-deprecating framing: he’s the guy who’s spent a career advocating for rigorous engineering — strong types, OCaml, careful testing, taking code review seriously — and now, in the era of coding agents, he’s back to tell you that all that stuff is now more important, not less. The talk is a tour of how three long-standing Jane Street practices — type systems, testing, and code review — translate into the agentic world, plus a candid section on why the firm is suddenly, after years of polite disinterest, getting interested in formal methods.
Where Jane Street is coming from

A few stats to anchor the perspective: Jane Street is a global trading firm operating across 200+ venues and 45+ countries, roughly 10% of the US equity market, 8% of US options, 20% of European ETFs. Roughly 2,000 of its 3,500 people write code regularly. That trading volume on top of fallible software is, in Ron’s words, terrifying, which is why the firm leans hard into rigorous engineering — though, importantly, calibrated to the value of correctness in each particular system, not as an undifferentiated dogma.
The firm is also unapologetically:
- AI-pilled — heavy agent deployment across the stack; a dedicated AI assistant team that, Ron admits, was probably a net drain on productivity until “the wind started blowing” around November of last year and uptake exploded.
- PL-pilled — OCaml as the primary language (with their own extensions), Python for ML/scripting, and a deep-rooted belief that programming languages are leverage.
With that context, Ron focuses on three areas where Jane Street’s approach is unusual, and a fourth where it’s openly changing.
1. Types: a design tool, not a nanny
The standard pitch for type systems is “you eliminate a class of bugs out of the box”: no null pointer errors, no out-of-bounds errors, the 70% of Google/Microsoft security vulnerabilities that are memory bugs simply gone. Jane Street’s flavored OCaml goes further — type-safe stack allocation, data-race prevention, and more.
But Ron’s real point is that the leveling-up happens when you stop thinking of types as a hand-slapping nanny and start thinking of them as a design tool — a way to express, enforce, and structure invariants of your program. He gives two crisp examples.
Making XSS impossible by construction

A naive string-interpolated HTML builder lets Little Bobby Tables walk right in. You can always remember to call the escape function — but better is making the mistake unrepresentable. Jane Street’s web framework uses a %html interpolation that requires a node.text (or equivalent) wrapper around user input; forget it and you get a type error. The local code looks almost the same, but the type system enforces the invariant globally — what Ron calls spooky action at a distance: the mistake can be made nowhere across thousands of files.
Making illegal states unrepresentable
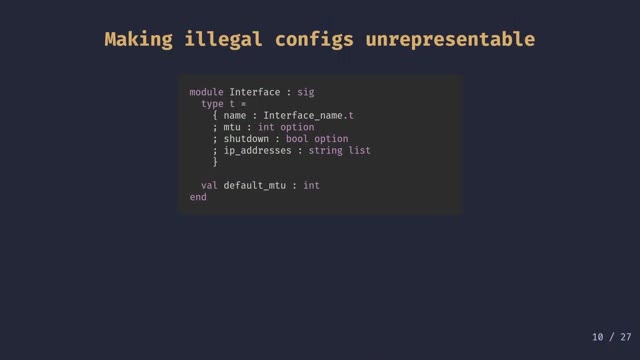
The catchphrase Ron “sort of by mistake” coined: make illegal states unrepresentable. The example is a network switch config modeled as a list of command variants — natural, but it lets you specify the MTU twice, or assert both shutdown true and shutdown false. Code reading that data has to invent semantics for cases that shouldn’t exist. The fix is a record type where fields that can appear at most once are option, fields that can repeat are list. The downstream code gets shorter and clearer, and the weird cases simply can’t be constructed.
Why this matters more in the agent era
Agents thrive on feedback, both at inference time and during training. Type systems give them an unusually good feedback channel:
- Fast — static checks beat any test suite for cycle time.
- Information-dense — a type error packs a lot of context into a few lines, which matters because “a million tokens sounds like a lot, but it kind of isn’t.”
- Consistent — LLMs are stochastic with bounded memory. A model told at token 0 which build command to use may not remember at token 230,000. Types are a rigorous, model-agnostic way to encode cross-cutting invariants that the system itself enforces.
“As a lot of people have been saying, verification is now the key bottleneck.”
2. Testing: expect tests, library-level simulation, and a defense of examples
Jane Street does all the standard things — unit tests, property tests with QuickCheck, fuzzing with AFL, full-system deterministic simulation with Antithesis, prod/dev side-by-side replays, historical test beds. But Ron focuses on two practices that are unusual: expect tests and library-level deterministic simulation.
What’s an expect test?

You write some code that produces output, leave the expected-output block empty, run the test, and the framework shows you a diff and lets you “accept” the output as the new expectation. Subsequent runs fail if the output drifts.
This sounds bad on its face — it seems to encourage lazy “looks good to me” tests rather than thinking carefully about properties. Ron concedes the concern but argues expect tests are, at their best, a tool for driving human understanding of the program under study:
- Carefully designed output (think plain-text “oscilloscopes” for hardware engineers, interleaved client/server message logs for distributed systems) lets a human absorb complex behavior at a glance.
- Committed examples encode intent: someone thought this scenario was worth pinning.
- When code changes, the diff includes both the logic change and the induced change to the behavioral trace — code review gains an extra dimension.
Library-level deterministic simulation
Above and beyond whole-system simulation, Jane Street simulates at the library level — mocking networks, clocks, services so that you can wire multiple programs together and watch them ping-pong in a test that runs in milliseconds. Ron is emphatic about iteration time:
“Getting it to a feels-instant is better still.”
Heavy whole-system tests are valuable, but the inner loop of “press a key and see the consequence” is irreplaceable. Library-level virtualization lets you slice the system at many levels and surface that to humans (and now agents) at each one.
In defense of example-based tests
Ron pushes back gently against property-testing orthodoxy. Most software is brittle — when it’s wrong by a little, it’s wrong by a lot — and that brittleness, painful as it is in production, is useful in testing: a small number of well-chosen examples can pin down a surprising fraction of behavior, especially when paired with a type system whose universal quantifications already cover the rest. He also pushes back on a remark from an earlier talk that you should only test against interfaces: some of the soft underbelly of software is in the implementation, and good example tests can probe it.
What changes for agents
The expect-test idiom turns out to be unusually agent-friendly:
- It surfaces behavior in text, which models still handle better than images.
- It closes another loop — agents can run, observe, propose, accept.
- It persists in the repo, so behavior changes show up in diffs forever.
- It’s fast enough to live inside an agent’s inner loop.
The combined effect is something like the dual of a spreadsheet: in a spreadsheet, data is everywhere and logic is invisible; in code, logic is compact and behavior is invisible; expect tests give you a compact logic representation and a visible behavioral unrolling, both as diffable artifacts.
3. Code review: more important than ever
Ron started at Jane Street with a narrow view — code review exists to stop you from losing money in a tight loop. Over time he came to see it as doing far more: spreading best practices, raising the bus factor, keeping code simple because someone else has to approve it, and frankly making the work more enjoyable.

In the agent era, all of this gets harder and more important:
- Agents need well-tended codebases. Ron cites the Anthropic experiment where agents collaboratively built a C compiler. The instructive part wasn’t the result — it was the failure mode: as the codebase grew messy, every change was more likely to break something else, and forward progress stalled. Agents are great at functional properties; they’re bad at preserving the non-functional properties (simplicity, factoring, lack of foot-guns) that they themselves depend on to keep working.
- Agents break the social contract of review. When a human hands you a feature, they invested in it; you respect that and prioritize the review. When a teammate YOLOs an agent-generated PR into your lap, that contract is broken — and reviewers notice.
- The smell signals you used to rely on are gone. Bad human code often looks bad; LLM code never makes grammar mistakes, so the usual correlations between surface polish and underlying quality go to zero.
- Reviewers’ eyes glaze over. Ron quotes an internal engineer: “When reviewing AI-generated code, I noticed myself checking out, finding it hard to focus, eyes glazing over.” This is a real problem when careful review is more necessary than before.
But agents help too: they make it cheaper to ask for big quality-improving refactors, they can split a fat feature into a reviewable stack, they can be used as an interactive oracle on the code before you talk to a human, and they can generate guided walk-throughs of a diff to lower a reviewer’s cognitive load.
A pointed audience exchange follows. Asked about automated code review, Ron’s answer is essentially: AI code review is great as an audit tool, but treating it as a replacement for review confuses the goal. Code review is about driving human understanding. An agent reviewing another agent’s code is harness engineering, not review.
4. The change of mind: formal methods
This is the section where Ron breaks from his usual pitch. For years he’s been politely telling formal-methods enthusiasts at PL conferences that Jane Street is super-duper not interested. That view is shifting.
The classic objection is cost. seL4 — ~8,700 lines of C, ~25 person-years, ~23 lines of proof per line of code, half a person-day per line — is not a model for how you build all your software. But two things shift the calculus:
- Models are quietly getting good at proof assistants. Hill-climbing on IMO and Putnam-style problems, Terry Tao reporting real productivity gains pairing with an agent on Lean proofs. The agent isn’t smarter than Tao at math; it’s just much better at Lean than he is. The combination is what matters.
- Agents are great specialty multiplexers. Ron emphasizes a point he thinks is underappreciated: agents aren’t that smart, but they’ve memorized the internet. Pair a domain expert with a “super-smart stenographer” that knows every proof tactic and every library, and things that were previously too expensive become tractable.
Concrete directions Jane Street is exploring:
- Refinement types — historically nice to read, painful to write. If the agent writes the annotations, the calculus changes.
- Differential verification — proving that a diff is a no-op with respect to certain properties, even when you can’t fully specify the system.
- Correct-by-construction refinement — the human writes a simple, obviously-correct functional reference implementation; an agent produces a fast imperative version along with a proof that the two are equivalent.
- Language design choices that ease proof. Verus works well with Rust partly because Rust’s ownership discipline sidesteps a lot of separation-logic complexity. Jane Street’s mode system in OCaml plays a similar role for them.
Ron is candid that this is a bet — current models may not be strong enough to deliver, and the world where formal methods wins is the world where it accelerates engineering rather than constraining it. But the team is fresh enough to it (“we kind of turned to each other and said, oh, maybe we should do this, like 8 weeks ago”) and excited enough to be hiring.
A questioner pushes on this: the famous verified systems (seL4, CompCert) are also designed for verifiability and often slower than their unverified counterparts. Doesn’t that constraint matter? Ron’s response: yes, and probably most ergonomic future workflows look like correct-by-construction — I write the slow obvious version, the agent produces the fast version with a proof. That’s also the kind of workflow where everyone gets their own performance engineer and proof engineer to borrow when they need one.
The throughline: human attention is the precious resource
Asked about goals like “people should never read or write code,” Ron is unimpressed:
“The precious resource remains human attention. What can people do? How can they add to the process? We should be thinking about maximizing people’s individual leverage.”
Everything in the talk — strong types, expect tests with readable traces, library-level simulation, real code review, a fresh interest in formal methods — is in service of that. Making the agents more effective is part of the story. Making humans more effective at understanding what the systems are doing is the other half, and Ron thinks it’s the under-discussed one.
A final closing comment from the Q&A worth pulling out: Ron initially worried that LLMs would write in some weird outsider style and corrode Jane Street’s carefully cultivated house idiom. In practice they’re very good at pattern-matching local style — sometimes too good, picking up the bad parts of a codebase along with the good. On balance: a relief.
Key takeaways
- Types are a design tool, not a safety net. The big wins come from making illegal states unrepresentable and using typed kernels to enforce invariants across distant parts of a codebase. Agents benefit from this even more than humans do, because type checks are fast, dense, and consistent in ways stochastic models are not.
- Verification is now the key bottleneck. Agents generate code cheaply; the scarce resource is checking it. Fast static checks, fast tests, and human-readable behavioral traces all become differentially more valuable.
- Expect tests are an under-appreciated agent-era idiom. They surface behavior in text, close the inner loop in milliseconds, and turn code review into a two-channel diff (logic and behavior).
- Library-level deterministic simulation beats whole-system simulation for inner-loop speed. Heavy end-to-end tests still matter; instant feedback matters more for iteration.
- Example-based tests are unreasonably effective. Software is brittle, types cover the universal cases, and a few well-chosen examples plus a thoughtful human pin down most of the rest — while teaching readers what the system actually does.
- Agents make code review more important, not less. They preserve functional properties but degrade non-functional ones (simplicity, factoring), and they’re the very property on which their future productivity depends. The social contract of review, the smell signals reviewers rely on, and reviewer attention itself all need rebuilding.
- “AI code review” is great as automated audit, but it doesn’t replace review. Review is for human understanding; conflating the two confuses the goal.
- Formal methods may finally be worth the cost — not because the models are mathematical geniuses, but because they’re competent stenographers in Lean/Coq/Verus and they pair well with domain experts. Correct-by-construction refinement (human writes a simple spec, agent produces a fast verified implementation) is the workflow Ron is most excited about.
- The goal is human leverage, not human absence. Tools and processes should be optimized to maximize what people can understand and decide. Maximizing agent throughput is half the story; maximizing human comprehension is the other half.
Source
📺 Now more than ever: building reliable software in the age of agents — Ron Minsky, Jane Street (~1h06m)