Weekly Paper Notes — one of the top picks from the May 17–23, 2026 CS paper digest. Area: AI / ML.
Authors: Ali Hatamizadeh, Yejin Choi, Jan Kautz (NVIDIA) arXiv: 2605.22791 · PDF · Code
TL;DR
Linear-attention models compress an unbounded history into a fixed-size recurrent state, but their active edit — the operation that overwrites stale associations with new ones — has historically been controlled by a single scalar gate that decides both how much old content to erase and how much new content to write. Gated DeltaNet-2 cleanly separates those two decisions into a channel-wise erase gate on the key side and a channel-wise write gate on the value side, while preserving KDA’s channel-wise decay. The change is small in equations, large in effect: at the 1.3B / 100B-token scale, it sets a new recurrent-attention frontier on RULER multi-key needle-in-a-haystack and real-world recall — and it keeps the same chunkwise WY training kernel KDA already shipped, so there is no throughput penalty.
What problem is the paper actually attacking?
Linear attention’s appeal is well-known: replace the quadratic softmax-attention matrix with a fixed-size recurrent state, get linear-time sequence mixing and constant-memory decoding. The cost is also well-known: a fixed-size matrix state has to absorb all of a long context’s associations, so retrieval suffers from interference — many key–value pairs landing in the same finite space.
The recurrent-attention lineage has been a steady sequence of fixes to that interference problem:
- Mamba-2 added a data-dependent scalar decay to give the state a global forgetting operation.
- DeltaNet replaced the additive write with a delta rule: subtract the value currently associated with the incoming key, then write the new value — a targeted overwrite of that key’s slot.
- Gated DeltaNet combined both: scalar decay (global forgetting) plus delta-rule edit (targeted overwrite).
- Kimi Delta Attention (KDA) refined the decay side from a scalar to a per-channel vector over key dimensions, so different key channels can decay at their own rate.
The paper’s observation is that every one of those refinements addressed one half of the active update. KDA gave decay channel-wise expressiveness, but the delta gate (called β in the literature) — the thing that controls the actual residual edit — was still a single scalar per head, and that scalar simultaneously controlled (a) which key coordinates of the old read get erased and (b) which value coordinates of the incoming value get committed. Those are operations on different axes of the state matrix. Tying them to one scalar is a modeling restriction, not a constraint of the delta rule itself.
The mechanism: Gated Delta Rule-2
Gated DeltaNet-2 replaces the single scalar β with two independent channel-wise gates:
- An erase gate
b_t ∈ [0,1]^{d_k}— one weight per key coordinate - A write gate
w_t ∈ [0,1]^{d_v}— one weight per value coordinate
The update rule becomes (paper’s Eq. 10):
S_t = ( I − k_t (b_t ⊙ k_t)ᵀ ) D_t S_{t−1} + k_t (w_t ⊙ v_t)ᵀ
where D_t = Diag(α_t) is KDA’s channel-wise decay diagonal.
Three things are worth noticing about this form:
- The write direction stays
k_t. The left factor of the erase term is still the raw key, so the delta rule’s “edit the association at keyk_t” property is preserved. The right factor — the read direction — becomesb_t ⊙ k_t, which is what makes the read channel-selective. - The write content becomes
w_t ⊙ v_t. The write is now value-channel-selective. - It nests the predecessors exactly. Set
b_t = β_t · 1andw_t = β_t · 1and you recover KDA. Further setα_t = α_t · 1and you recover Gated DeltaNet. So nothing is lost — Gated DeltaNet-2 just learns to escape those tied subspaces when erase and write need different channel structure.
The two gates come from independent linear projections of the token representation followed by sigmoids; the log-decay branch follows Gated DeltaNet’s parameterization unchanged (computed in fp32 to avoid cumulative-decay precision loss).
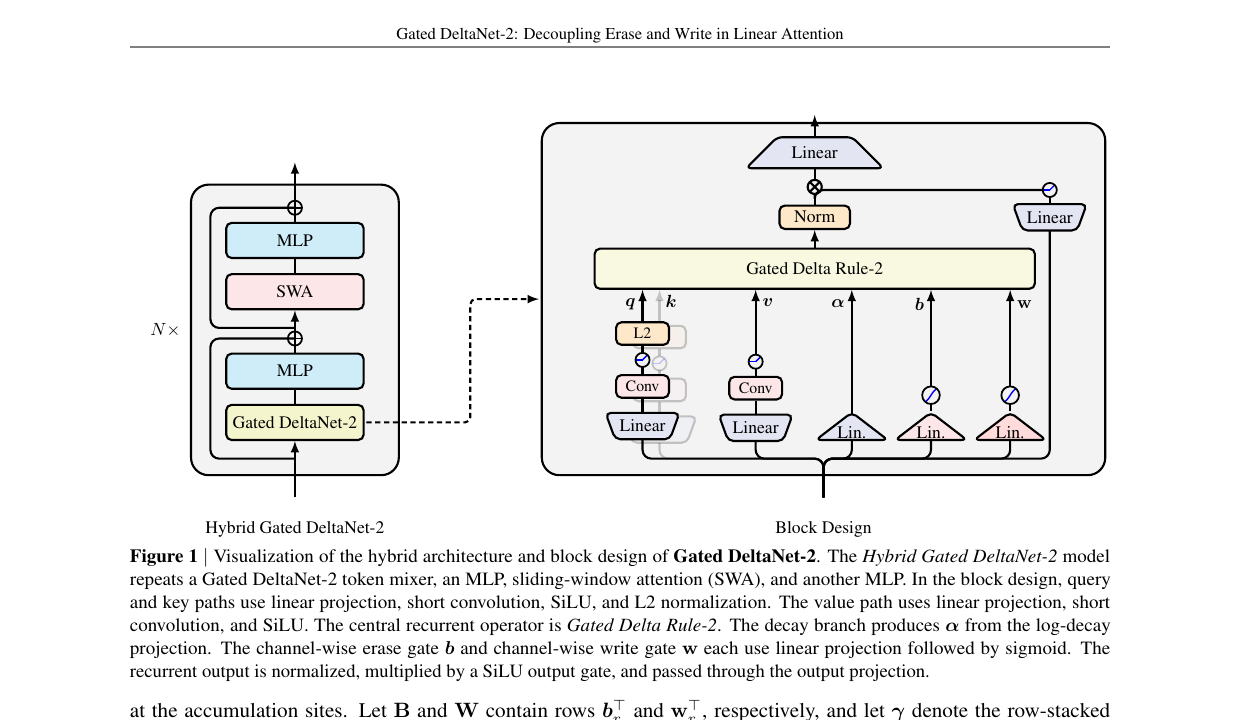
Architecture: hybrid Gated DeltaNet-2 block

The block looks like a familiar Transformer-style residual unit: query/key/value projections with short causal convolutions and SiLU, L2 normalization on q/k for stability, RMS-norm on the recurrent output, and a separate SiLU output gate. The mechanical novelty is the three small parallel branches at the bottom of the block — α, b, w — that produce the per-channel decay and the two gates from independent linear projections.
The hybrid model (left side of the figure) interleaves Gated DeltaNet-2 with sliding-window attention (SWA) in the standard recurrent-attention hybrid pattern: the recurrent mixer compresses long histories into the fixed-size state, while SWA handles exact local interactions (short shifts, comparisons, local retrieval) within a 2K window. Linear sequence scaling is preserved; the attention cache stays bounded.
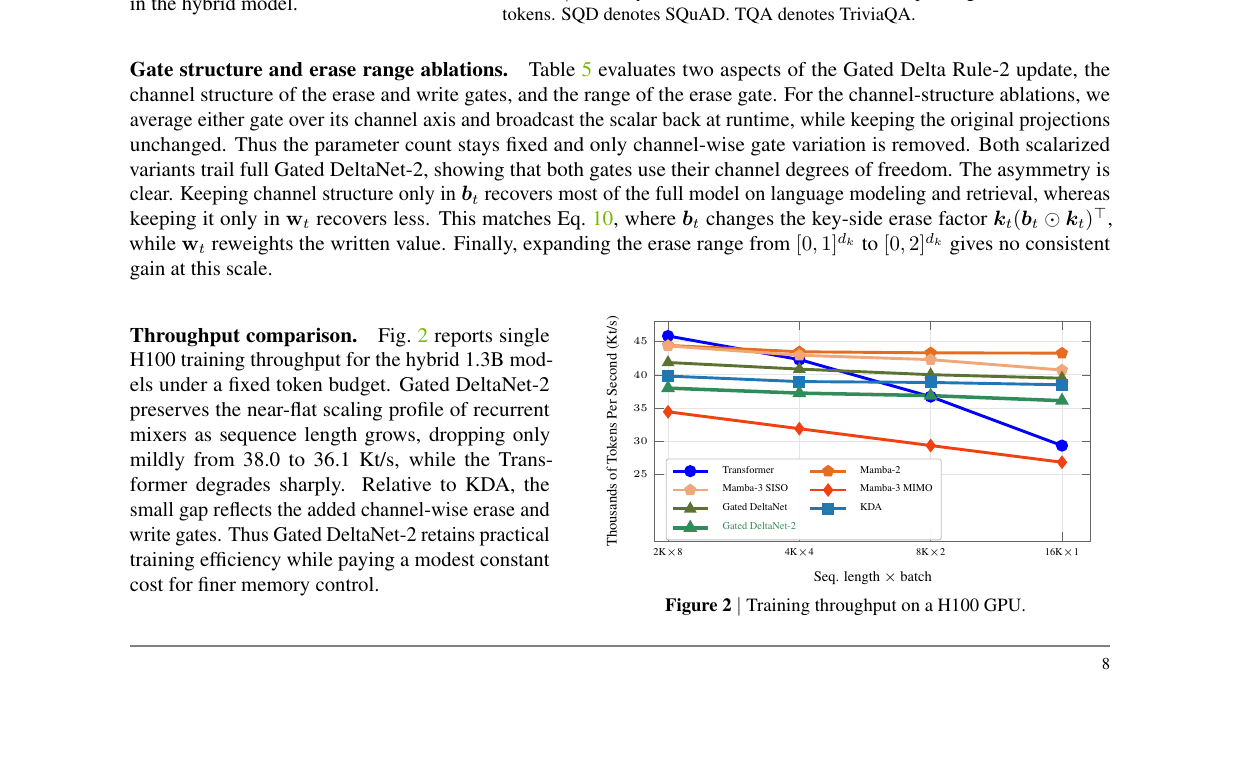
Why training stays fast
The most important practical claim is that decoupling the gates does not break the chunkwise WY-form kernel that makes KDA trainable at scale. The trick (Section 3.3 of the paper) is to absorb the cumulative channel-wise decay γ into the two factors of each rank-one erase term:
ē = γ ⊙ (B ⊙ K), Z = W ⊙ V
The intra-chunk computation becomes a triangular solve A = (I + tril(ē·K̄ᵀ, −1))⁻¹ followed by two WY auxiliaries Y = A·ē (erase-side) and U = A·Z (write-side), and the end-of-chunk state and output blocks have exactly the same matrix shapes as KDA’s. The only change is how Y and U are formed.
The authors implement this with fused Triton kernels via the UT transform. Backward is slightly more involved than KDA — the channel-wise gates can no longer be factored outside the dot products that accumulate gradients into the auxiliary A — but the matrix shapes are unchanged, so cache behavior and memory layout stay the same.
Results at the 1.3B / 100B-token scale
Every method is matched on parameter count, training tokens (100B FineWeb-Edu), optimizer, and sequence length (4K, hybrid models with 2K SWA window). Two takeaways from the headline tables:
Language modeling + commonsense (Table 2). Gated DeltaNet-2 wins the average in both recurrent-only and hybrid settings, beating Mamba-2, Gated DeltaNet, KDA, and both SISO/MIMO Mamba-3 variants. Since the recurrent state size is held constant, the improvement points to a stronger update rule, not more memory.
RULER needle-in-a-haystack (Table 3). This is where the gate decoupling pays off most. On Single-NIAH at 8K (S-NIAH-2 / S-NIAH-3) and on Multi-Key NIAH (MK-NIAH-1), the recurrent Gated DeltaNet-2 substantially outperforms KDA — the prior best recurrent. The interpretation lines up with the design: the key-side erase gate selectively protects or revises key channels (so old associations don’t get scrambled when a new one is written), while the value-side write gate controls which value channels enter the state (so noisy or distractor values don’t dilute clean ones). MK-NIAH-1, in particular, requires separating competing associations stored in the same fixed state — exactly the regime where a single scalar gate is most restrictive.
Real-world recall (Table 4). The same pattern on noisy real-world retrieval (SWDE, SQuAD, FDA, TriviaQA, NQ, DROP). Gated DeltaNet-2 is the best recurrent average and the best hybrid average; the wins are largest on the extraction-heavy and distractor-heavy tasks.
Ablations (Table 5). Killing either gate (w-only with scalar b, or b-only with scalar w) costs ~3 points on MK-NIAH-1. Both gates need to be channel-wise — they’re doing different jobs.
Why this matters
Long-context retrieval has been the most persistent open problem for fixed-state recurrent attention. The dominant pattern in the field for the last two years has been “use a softmax-attention layer somewhere in the stack to recover what the recurrent state lost” — that’s exactly what the hybrid SWA variants do. Gated DeltaNet-2 doesn’t dispense with hybrids, but it noticeably shrinks the gap the SWA layer has to close, which matters because the SWA layer is the part that brings back a (bounded) cache. A stronger recurrent layer means a smaller window can suffice, which means lower memory at long context lengths.
The bigger point: the recurrent-attention design space still has untapped axes of expressiveness that cost essentially nothing in throughput. Decoupling erase from write was sitting in plain sight — KDA decoupled decay channels, and this paper just applied the same lesson to the active edit. Worth watching whether the same idea propagates back into Mamba-3’s exponential-trapezoidal recurrence, which currently has no analog of the delta-rule residual.
Read alongside
- Yang et al., Gated DeltaNet (2024) — the immediate predecessor and the natural ablation baseline.
- Kimi Delta Attention (KDA) — Moonshot’s channel-wise-decay refinement that this paper builds on directly.
- Mamba-3 (Han et al., 2026) — the SSM-route alternative that this paper compares against (SISO and MIMO).
- The RULER benchmark paper (Hsieh et al., 2024) for context on S-NIAH and MK-NIAH evaluation.
Links
📄 arXiv abstract (2605.22791) · 📄 PDF · 💾 github.com/NVlabs/GatedDeltaNet-2
Part of the Weekly CS Paper Digest series. Summary written from a close read of the preprint; figures cropped from the arXiv PDF (©NVIDIA 2026) and reproduced here under fair use for educational commentary.